GPT-2 Transformatör Dil Modellerinin Görselleştirilmesi
2019'da makine öğreniminin baş döndürücü bir uygulamasına tanık olduk. OpenAI GPT-2, mevcut dil modellerinin üretebileceğini tahmin ettiğimizin ötesinde, tutarlı ve tutkulu makaleler yazma konusunda etkileyici bir yetenek sergiledi.
Alammar, J (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/
(Bu yazı Giriş Seviyesindeki herkesin anlayabilmesi amacıyla Jay Alammar tarafından hazırlanan The Illustrated GPT-2 yazısının orijinaline bağlı kalınarak düzenlenmiş çevirisidir.)

GPT-2 özellikle yeni bir mimari değildi; mimarisi yalnızca kod çözücü transformatörüne çok benzer. Ancak GPT2, çok büyük bir veri kümesi üzerinde eğitilmiş, çok büyük, dönüştürücü tabanlı bir dil modeliydi. Bu yazıda modelin sonuçlarını üretmesini sağlayan mimariye bakacağız. Öz-dikkat katmanının derinliklerine ineceğiz. Daha sonra dil modellemenin ötesinde yalnızca kod çözücü transformatörüne yönelik uygulamalara bakacağız.
Buradaki amacım aynı zamanda daha önceki yazım olan The Illustrated Transformer’ı , transformatörlerin iç işleyişini ve orijinal makaleden bu yana nasıl geliştiklerini açıklayan daha fazla görselle desteklemektir . Umudum, bu görsel dilin daha sonraki Transformer tabanlı modellerin iç işleyişi gelişmeye devam ettikçe açıklanmasını kolaylaştıracağını umuyorum.
İçindekiler
- Bölüm 1: GPT2 ve Dil Modellemesi
- Dil Modeli Nedir?
- Dil Modelleme için Transformatörler
- BERT’ten Tek Fark
- Trafo Bloğunun Evrimi
- Beyin Cerrahisinde Hızlandırılmış Kurs: GPT-2'nin İçine Bakış
- İçeriye Daha Derin Bir Bakış
- 1. bölümün sonu: Bayanlar ve Baylar GPT-2
- Bölüm 2: Resimli Kişisel Dikkat
- Kişisel Dikkat (maskelemeden)
- 1- Sorgu, Anahtar ve Değer Vektörleri Oluşturun
- 2- Skor
- 3- Toplam
- Resimli Maskeli Öz-Dikkat
- GPT-2 Maskelenmiş Öz-Dikkat
- Dil modellemenin ötesinde
- Başardın!
- Bölüm 3: Dil Modellemenin Ötesinde
- Makine Çevirisi
- Özetleme
- Öğrenimi Aktar
- Müzik Üretimi
Bölüm #1: GPT2 ve Dil Modelleme
Peki dil modeli tam olarak nedir?
Dil Modeli Nedir?
The Illustrated Word2vec’de dil modelinin ne olduğuna baktık; temel olarak cümlenin bir kısmına bakıp sonraki kelimeyi tahmin edebilen bir makine öğrenme modeli. En ünlü dil modelleri, o anda yazdıklarınıza göre bir sonraki kelimeyi öneren akıllı telefon klavyeleridir.

Bu anlamda GPT-2'nin temelde bir klavye uygulamasının sonraki kelime tahmin özelliği olduğunu ancak telefonunuzun sahip olduğundan çok daha büyük ve daha karmaşık olduğunu söyleyebiliriz. GPT-2, OpenAI araştırmacılarının araştırma çabasının bir parçası olarak internetten taradığı WebText adı verilen 40 GB’lık devasa bir veri kümesi üzerinde eğitildi. Depolama boyutu açısından karşılaştırma yapmak gerekirse, kullandığım klavye uygulaması SwiftKey 78 MB yer kaplıyor. Eğitilmiş GPT-2'nin en küçük çeşidi, tüm parametrelerini saklamak için 500 MB’lık depolama alanı kaplıyor. En büyük GPT-2 çeşidi 13 kat daha büyük olduğundan 6,5 GB’tan fazla depolama alanı kaplayabilir.

GPT-2 ile denemeler yapmanın harika bir yolu AllenAI GPT-2 Explorer’ı kullanmaktır . Bir sonraki kelimeye ilişkin on olası tahmini (olasılık puanlarıyla birlikte) görüntülemek için GPT-2'yi kullanır. Bir kelimeyi seçip pasajı yazmaya devam etmek için sonraki tahmin listesini görebilirsiniz.
Dil Modelleme için Transformatörler
The Illustrated Transformer’da gördüğümüz gibi , orijinal transformatör modeli bir kodlayıcı ve kod çözücüden oluşur; her biri transformatör blokları diyebileceğimiz şeylerin bir yığınıdır. Bu mimari uygundu çünkü model, kodlayıcı-kod çözücü mimarilerinin geçmişte başarılı olduğu bir sorun olan makine çevirisini ele alıyordu.
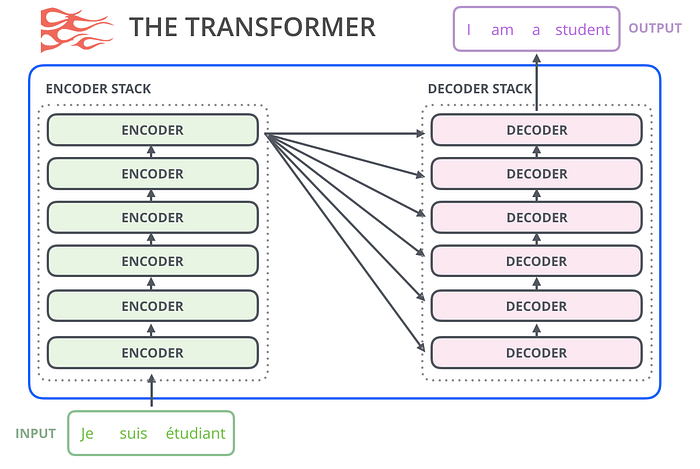
Sonraki araştırma çalışmalarının çoğunda, mimarinin ya kodlayıcıyı ya da kod çözücüyü değiştirdiği ve yalnızca bir transformatör bloğu yığını kullandığı, bunları pratik olarak mümkün olduğu kadar yükseğe istiflediği, onlara çok büyük miktarda eğitim metni beslediği ve çok büyük miktarda hesaplamayı çöpe attığı görüldü. (bu dil modellerinden bazılarını eğitmek için yüzbinlerce dolar, AlphaStar durumunda muhtemelen milyonlarca dolar ).

Bu blokları ne kadar yükseğe yığabiliriz? Farklı GPT2 model boyutları arasındaki ana ayırt edici faktörlerden birinin bu olduğu ortaya çıktı:

BERT’ten Tek Fark
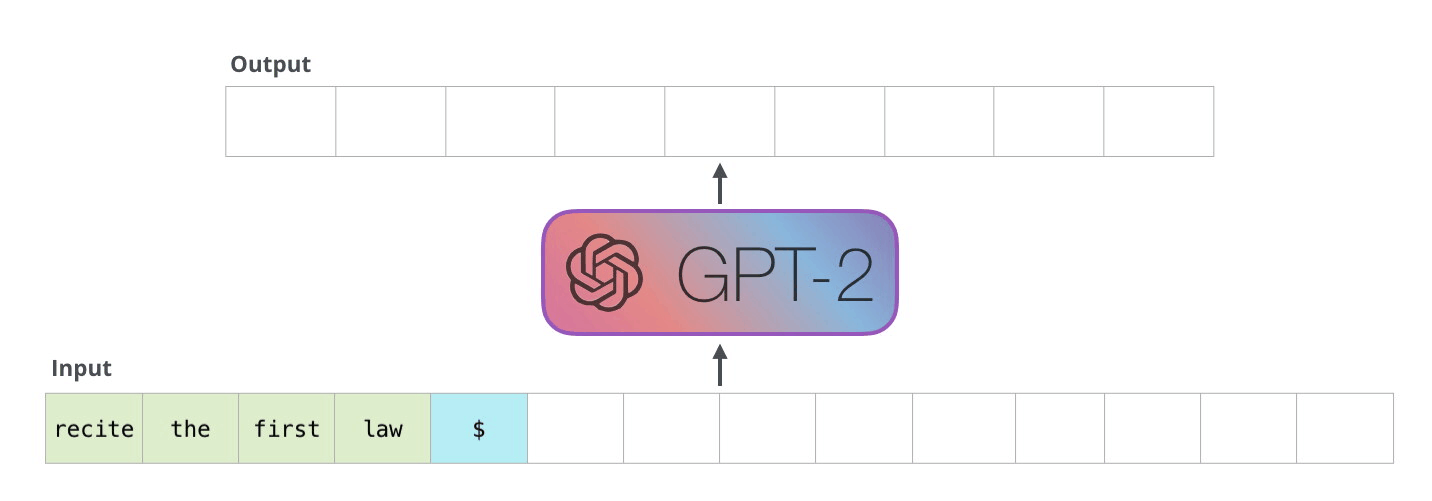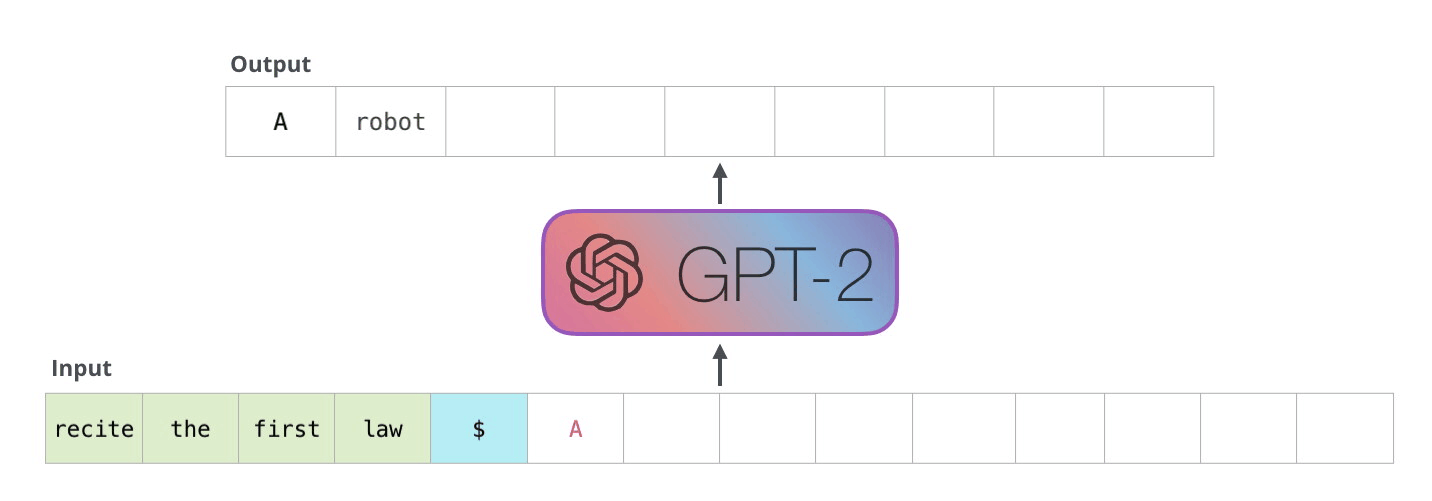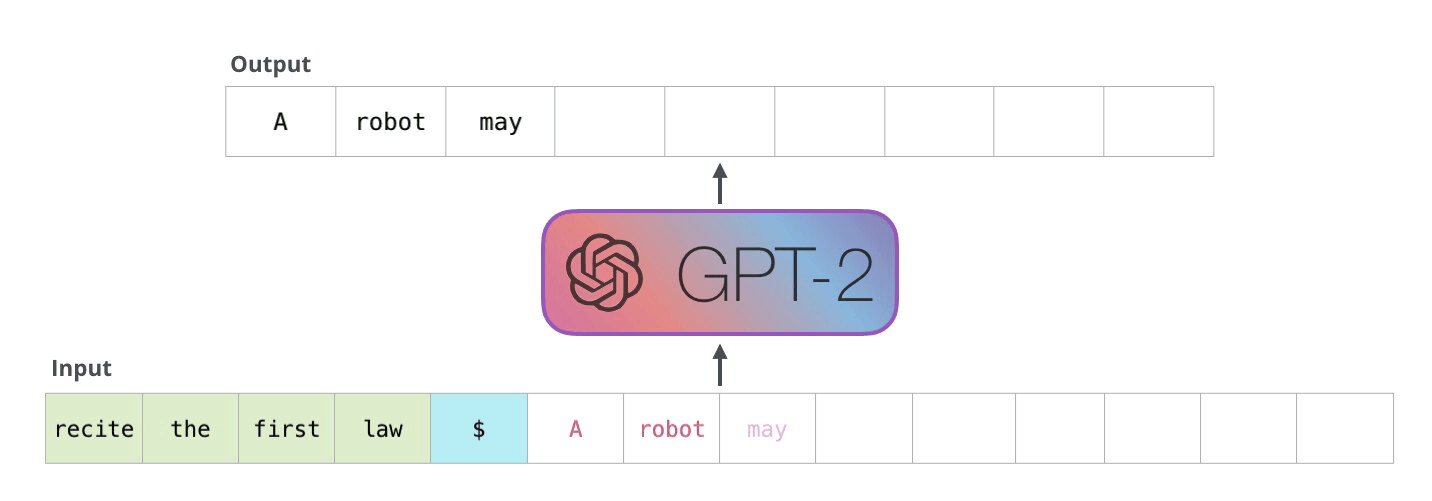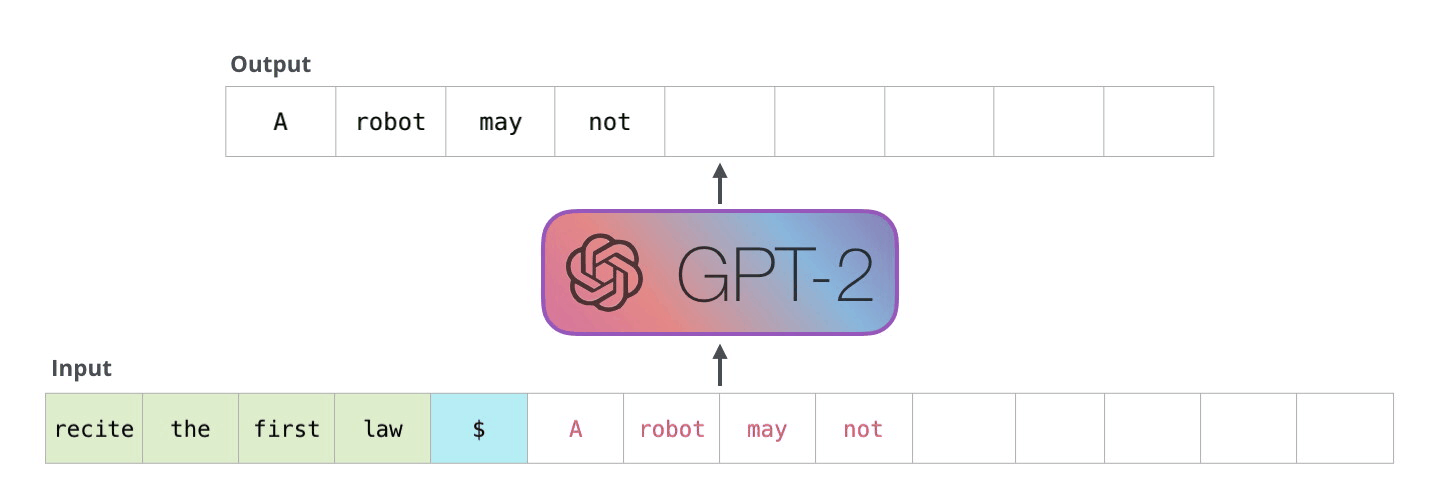
Robotiğin Birinci Yasası
Bir robot bir insana zarar veremez veya eylemsizlik nedeniyle bir insanın zarar görmesine izin veremez.
GPT-2, transformatör kod çözücü blokları kullanılarak oluşturulmuştur. BERT ise transformatör enkoder bloklarını kullanıyor. Farkı bir sonraki bölümde inceleyeceğiz. Ancak ikisi arasındaki önemli farklardan biri, GPT2'nin, geleneksel dil modellerinde olduğu gibi, her seferinde bir token çıkarmasıdır. Örneğin, iyi eğitilmiş bir GPT-2'den robotiğin birinci yasasını okumasını isteyelim:
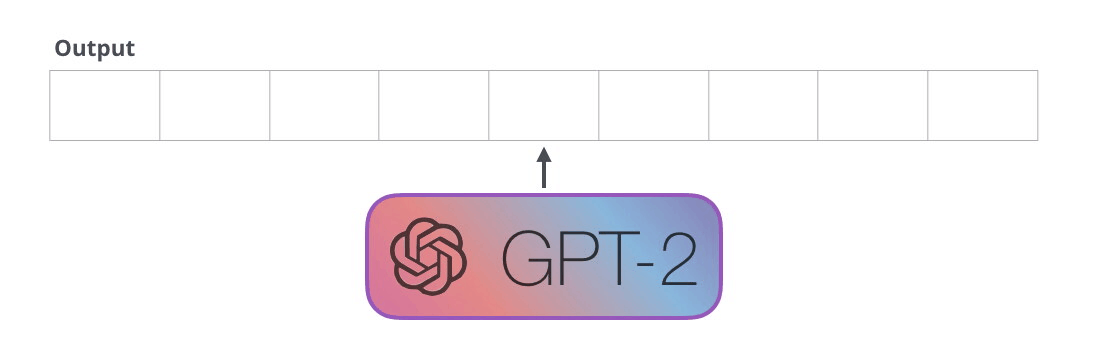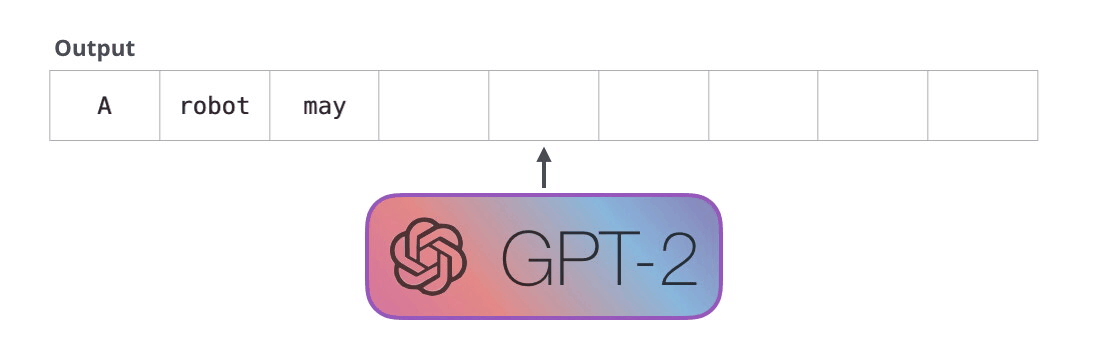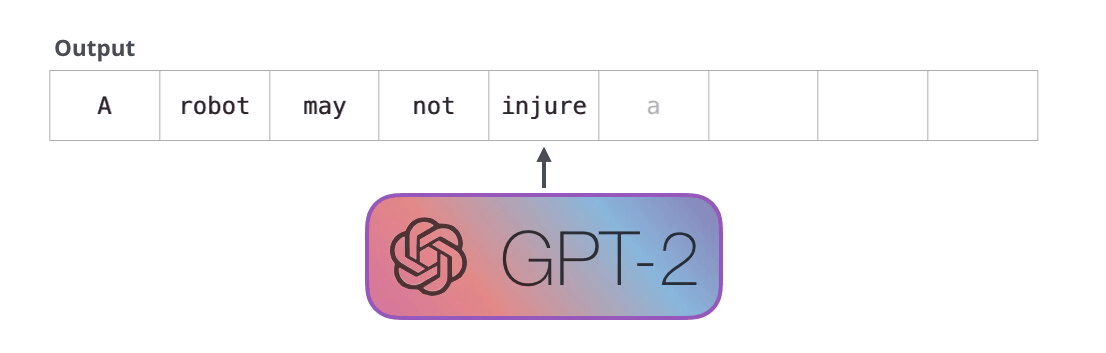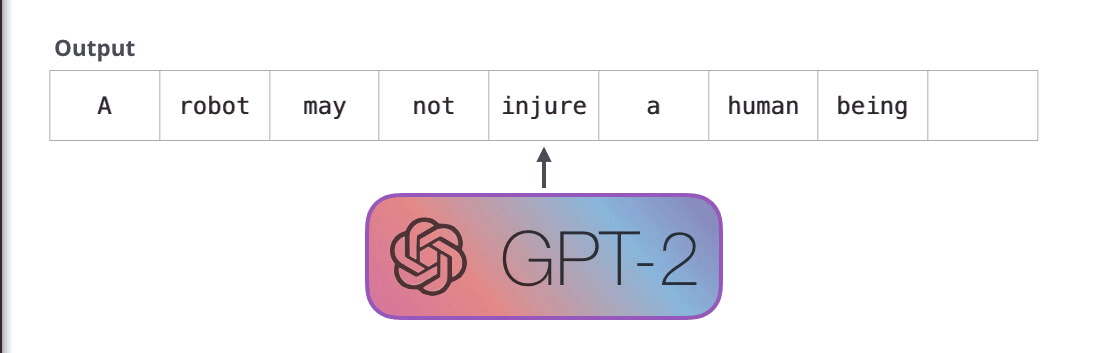
Bu modellerin gerçekte çalışma şekli, her token üretildikten sonra o tokenın girdi dizisine eklenmesidir. Ve bu yeni dizi, bir sonraki adımda modele girdi oluyor. Bu “otomatik regresyon” adı verilen bir fikirdir. Bu, RNN’leri mantıksız derecede etkili kılan fikirlerden biridir .
GPT2 ve TransformerXL ve XLNet gibi daha sonraki bazı modeller, doğası gereği otomatik gerilemelidir. BERT öyle değil. Bu bir takastır. Otomatik regresyonu kaybeden BERT, daha iyi sonuçlar elde etmek için bağlamı kelimenin her iki tarafına da dahil etme yeteneğini kazandı. XLNet, bağlamı her iki tarafa da dahil etmenin alternatif bir yolunu bulurken otoregresyonu geri getiriyor.
Transformatör Bloğunun Evrimi
İlk transformatör dökümanı iki tür transformatör bloğunu tanıttı:
Kodlayıcı Bloğu
Birincisi kodlayıcı bloğu:
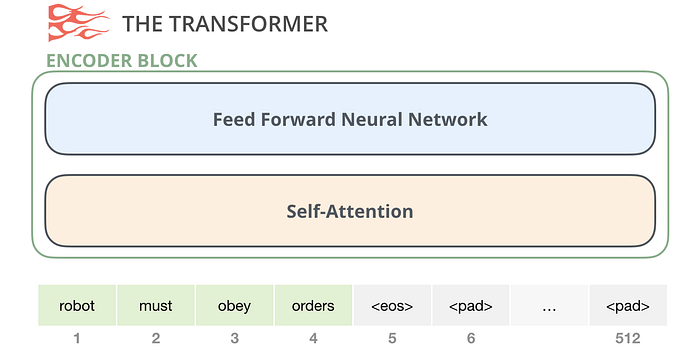
Orijinal transformatör kağıdından gelen bir kodlayıcı bloğu, belirli bir maksimum dizi uzunluğuna (örneğin 512 token) kadar girdileri alabilir. Bir giriş dizisinin bu sınırdan daha kısa olmasında sorun yoktur, yalnızca dizinin geri kalanını doldurabiliriz.
Kod Çözücü Bloğu
İkincisi, kodlayıcı bloğundan küçük bir mimari farklılığa sahip olan kod çözücü bloğu vardır; kodlayıcının belirli bölümlerine dikkat etmesini sağlayan bir katmandır:
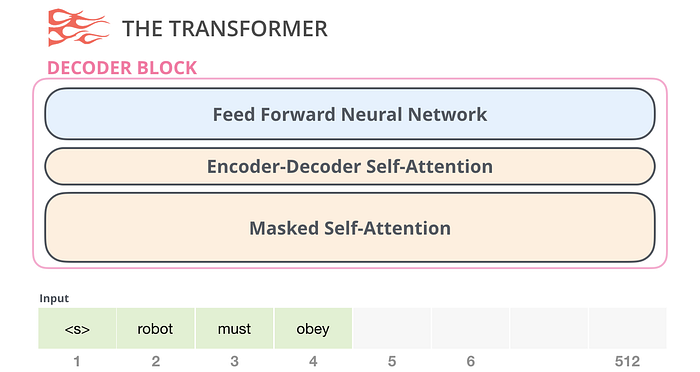
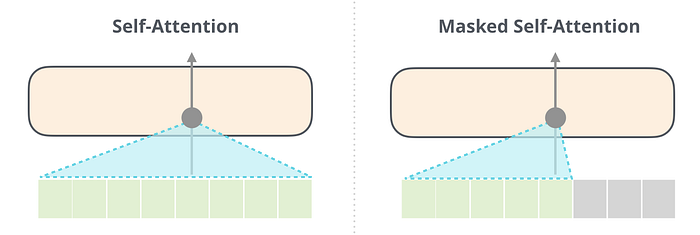
Buradaki öz-dikkat katmanındaki önemli bir fark, gelecekteki belirteçleri maskelemesidir, kelime BERT gibi [maske] olarak değiştirerek değil, kişisel dikkat hesaplamasına müdahale ederek, sağ taraftaki belirteçlerden gelen bilgileri engelleyerek konum hesaplanıyor.
Örneğin, #4 numaralı konumun yolunu vurgulayacak olursak, yalnızca mevcut ve önceki tokenlara katılmasına izin verildiğini görebiliriz:
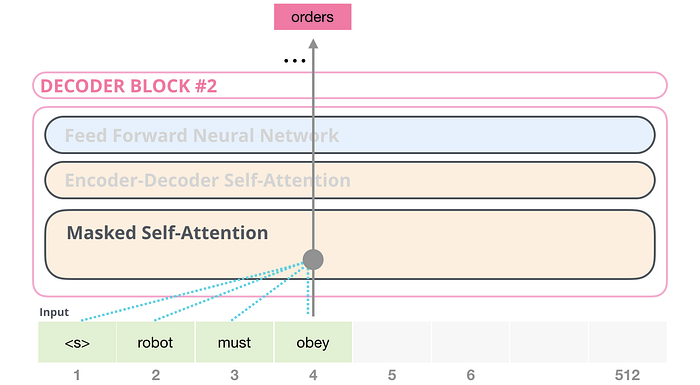
Öz-dikkat (BERT’in kullandığı) ile maskelenmiş öz-dikkat (GPT-2'nin kullandığı) arasındaki ayrımın net olması önemlidir. Normal bir kişisel dikkat bloğu, bir pozisyonun sağındaki belirteçlerde zirveye çıkmasına izin verir. Maskelenmiş öz-dikkat bunun olmasını engeller:
Yalnızca Kod Çözücü Bloğu
Orijinal makalenin ardından, Uzun Dizileri Özetleyerek Vikipedi Oluşturmak , transformatör bloğunun dil modellemesi yapabilen başka bir düzenlemesini önerdi. Bu model Transformer kodlayıcıyı çöpe attı. Bu nedenle modele “Transformer-Decoder” adını verelim. Bu eski transformatör tabanlı dil modeli, altı transformatör kod çözücü bloğundan oluşan bir yığından oluşuyordu:

Kod çözücü blokları aynıdır. İlkini genişlettim, böylece onun öz-dikkat katmanının maskelenmiş varyant olduğunu görebilirsiniz. Modelin artık belirli bir segmentte 4.000'e kadar tokeni adresleyebildiğine dikkat edin; bu, orijinal transformatördeki 512'ye göre büyük bir yükseltmedir.
Bu bloklar, ikinci öz-dikkat katmanını ortadan kaldırmaları dışında orijinal kod çözücü bloklarına çok benziyordu. Benzer bir mimari , her seferinde bir harf/karakter tahmin eden bir dil modeli oluşturmak için Daha Derin Öz-Dikkat ile Karakter Düzeyinde Dil Modellemesinde incelenmiştir .
OpenAI GPT-2 modeli bu yalnızca kod çözücü bloklarını kullanır.
Beyin Cerrahisinde Hızlandırılmış Kurs: GPT-2'nin İçine Bakış
İçine bak göreceksin, Kelimeler beynimin derinliklerini kesiyor. Gök gürültüsü yanıyor, hızla yanıyor, Kelimelerin bıçağı beni deli ediyor, delirtiyor evet. ~ Budgie
Ameliyat masamıza eğitimli bir GPT-2 yerleştirelim ve nasıl çalıştığına bakalım.

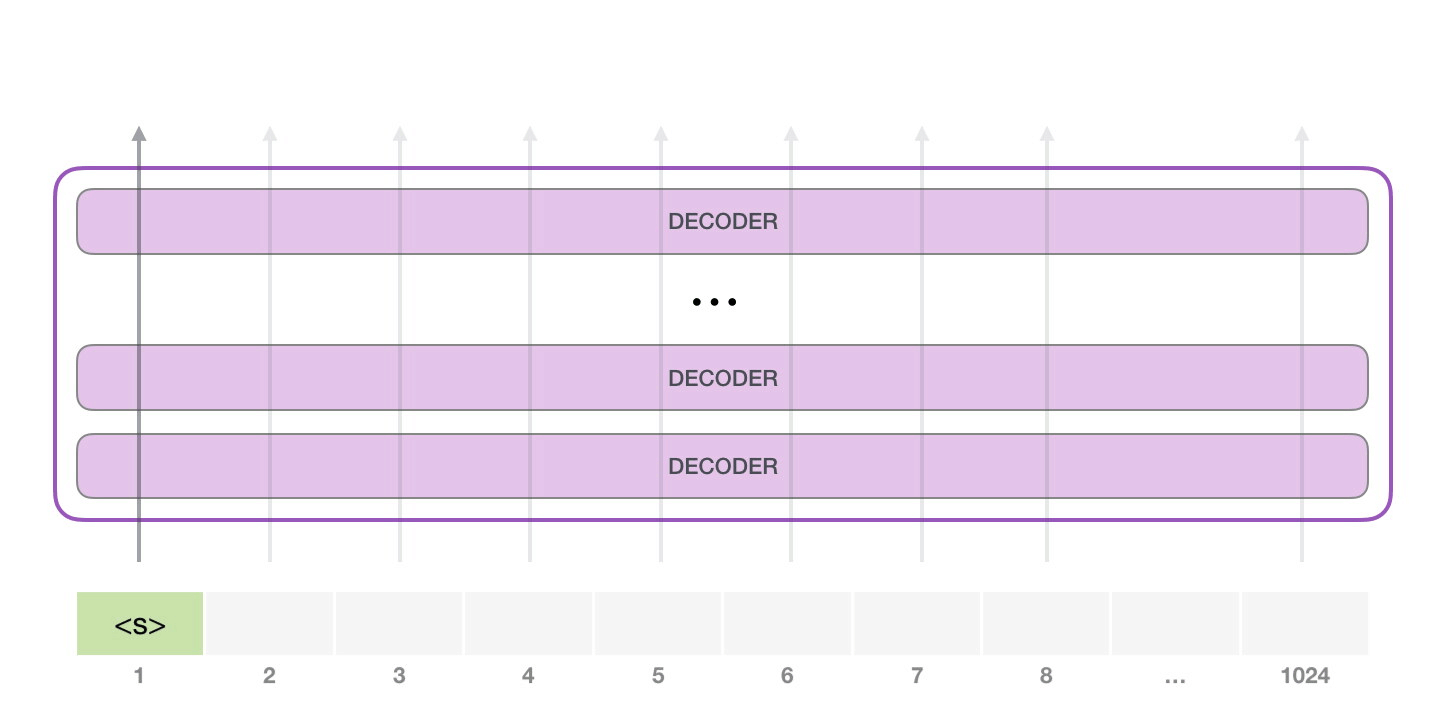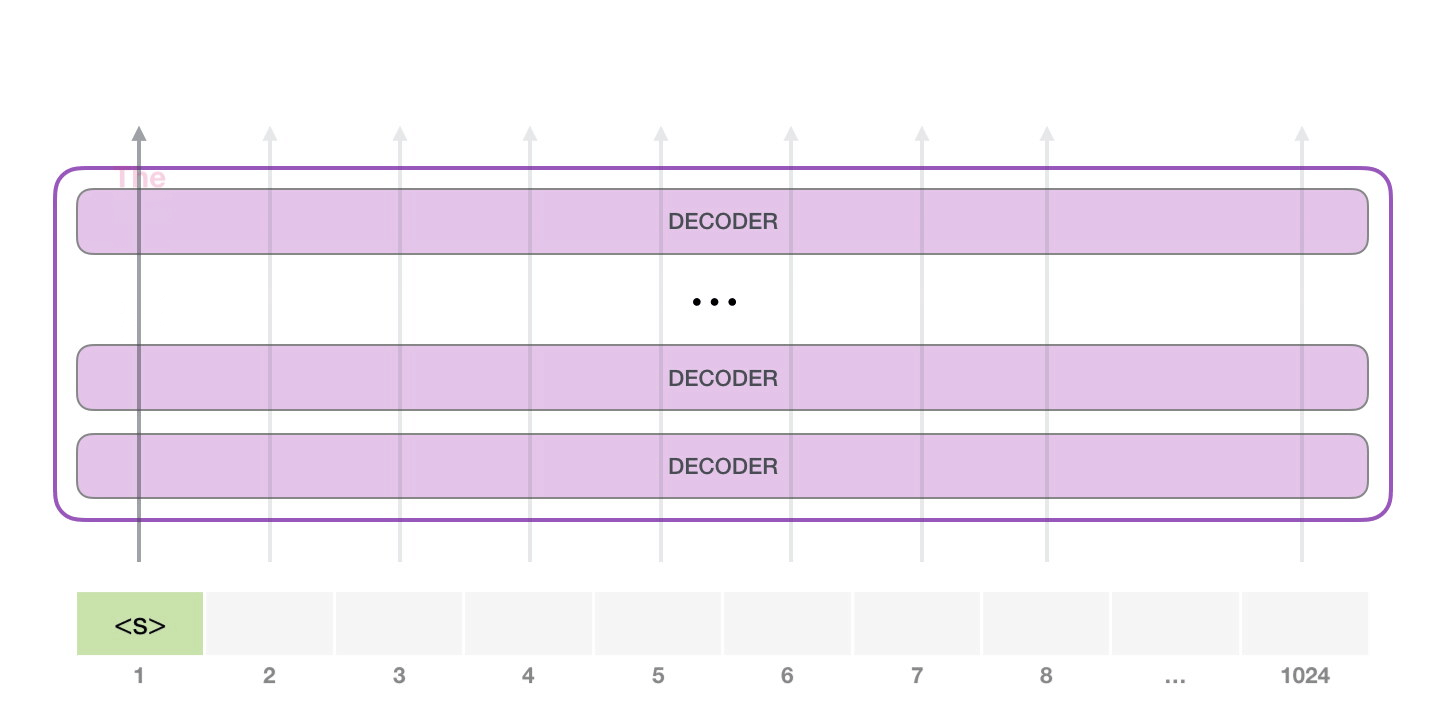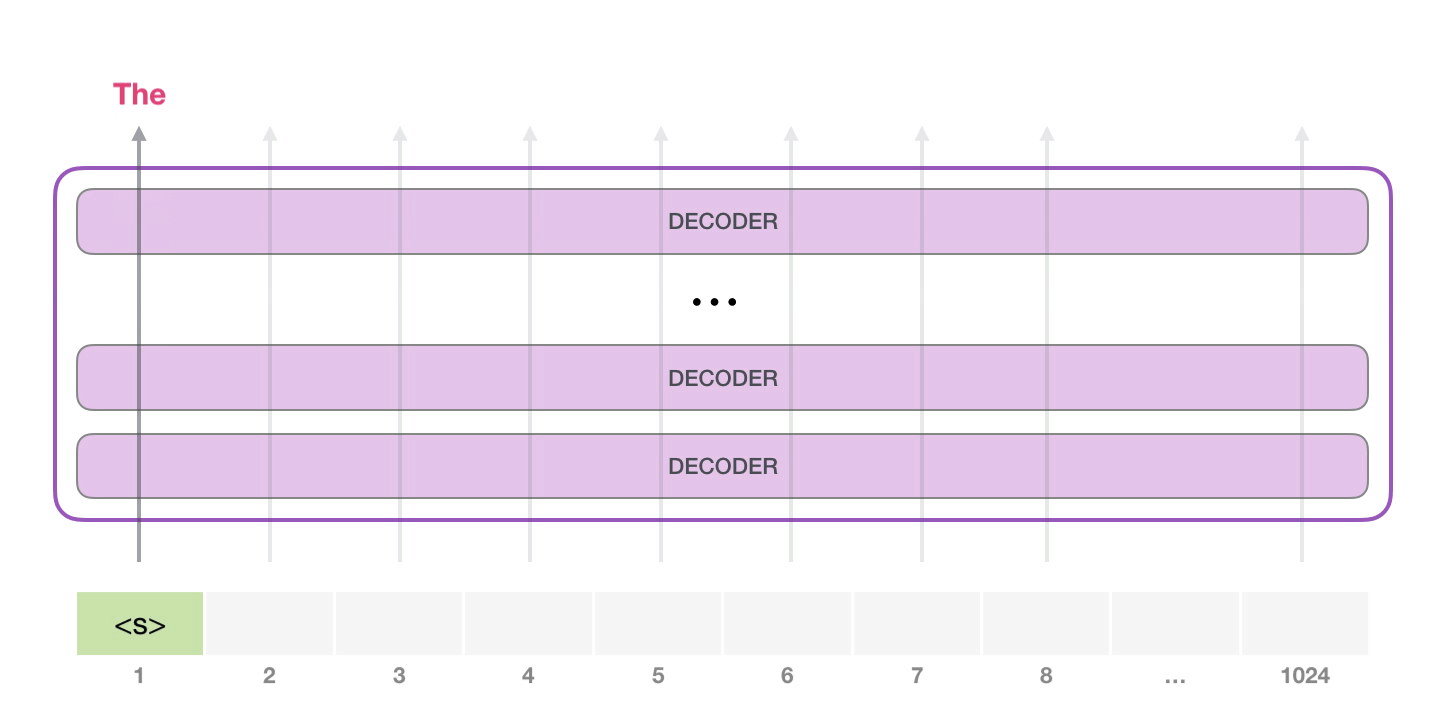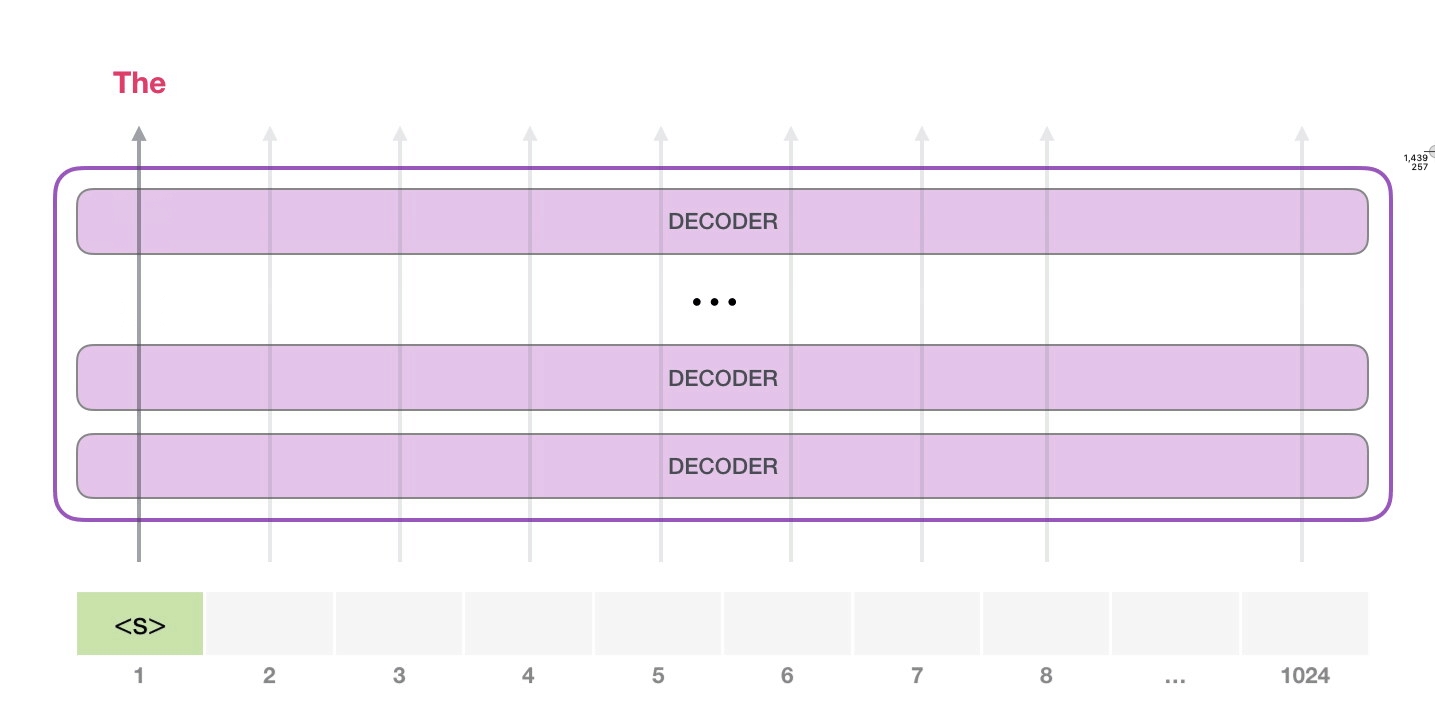
GPT-2 1024 tokenı işleyebilir. Her token kendi yolu boyunca tüm kod çözücü bloklarından akar.
Eğitimli bir GPT-2'yi çalıştırmanın en basit yolu, onun kendi başına dolaşmasına izin vermektir (buna teknik olarak koşulsuz örnekler oluşturmak denir ) alternatif olarak, ona belirli bir konu hakkında konuşması için bir komut verebiliriz (diğer bir deyişle etkileşimli koşullu örnekler oluşturmak). Karışık durumda, ona basitçe başlangıç tokenını verebiliriz ve kelimeler üretmeye başlamasını sağlayabiliriz (eğitimli model, <|endoftext|>başlangıç tokenı olarak kullanır. Onun yerine onu çağıralım <s>).
Modelin yalnızca bir giriş tokenı vardır, dolayısıyla bu yol tek etkin olan olacaktır. Belirteç tüm katmanlar boyunca art arda işlenir, ardından bu yol boyunca bir vektör üretilir. Bu vektör, modelin kelime dağarcığına göre puanlanabilir (modelin bildiği tüm kelimeler, GPT-2 durumunda 50.000 kelime). Bu durumda en yüksek olasılığa sahip tokenı seçtik. Ancak işleri kesinlikle karıştırabiliriz; klavye uygulamanızda önerilen kelimeye tıklamaya devam ederseniz, bazen tek çıkışın önerilen ikinci veya üçüncü kelimeye tıklamanız olduğu tekrarlayan döngülerde sıkışıp kalabileceğini biliyorsunuz. Aynı şey burada da olabilir. GPT-2'de, modelin üst kelime dışındaki kelimeleri örneklemeyi dikkate almasını sağlamak için kullanabileceğimiz top-k adında bir parametre vardır (top-k = 1 olduğunda durum böyledir).
Bir sonraki adımda, ilk adımdaki çıktıyı girdi sıramıza ekliyoruz ve modelin bir sonraki tahminini yapmasını sağlıyoruz:

Bu hesaplamada aktif olan tek yolun ikinci yol olduğuna dikkat edin. GPT-2'nin her katmanı, ilk simgeye ilişkin kendi yorumunu korumuştur ve bunu ikinci simgeyi işlerken kullanacaktır (bununla ilgili daha ayrıntılı bilgiyi, öz-dikkat hakkındaki aşağıdaki bölümde ele alacağız). GPT-2, ilk tokenı ikinci tokenın ışığında yeniden yorumlamaz.
İçeriye Daha Derin Bir Bakış
Giriş Kodlaması
Modeli daha yakından tanımak için daha fazla ayrıntıya bakalım. Girişten başlayalım. Daha önce tartıştığımız diğer NLP modellerinde olduğu gibi, model, eğitilmiş bir modelin parçası olarak elde ettiğimiz bileşenlerden biri olan, giriş sözcüğünün kendi yerleştirme matrisine yerleştirilmesine bakar.
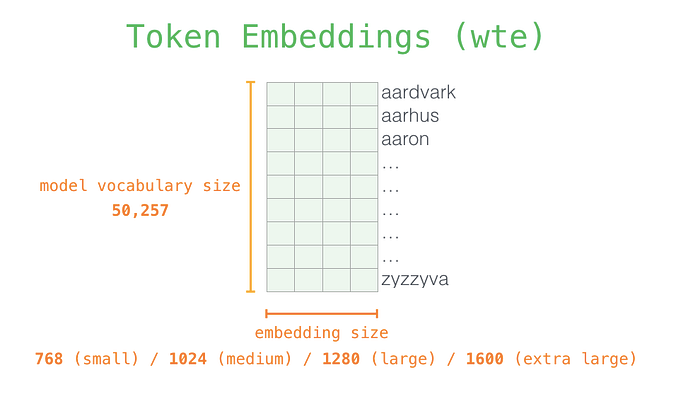
Her satır, bir kelime yerleştirmesidir: bir kelimeyi temsil eden ve anlamının bir kısmını yakalayan sayıların bir listesi. Bu listenin boyutu farklı GPT2 model boyutlarında farklıdır. En küçük model, kelime/belirteç başına 768'lik bir gömme boyutu kullanır.
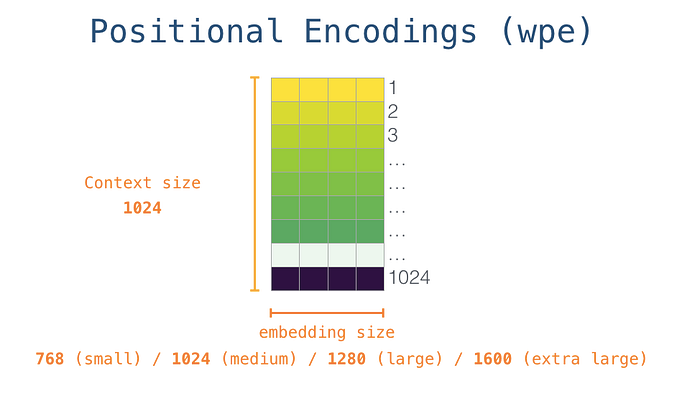
Başlangıçta, başlangıç tokenının <s>yerleştirme matrisine yerleştirilmesine bakıyoruz. Bunu modeldeki ilk bloğa aktarmadan önce, konumsal kodlamayı (transformatör bloklarına sıradaki kelimelerin sırasını gösteren bir sinyal) dahil etmemiz gerekir. Eğitilen modelin bir kısmı, girişteki 1024 konumun her biri için konumsal kodlama vektörü içeren bir matristir.
Bununla, giriş kelimelerinin ilk transformatör bloğuna iletilmeden önce nasıl işlendiğini ele aldık. Ayrıca eğitilmiş GPT-2'yi oluşturan ağırlık matrislerinden ikisini de biliyoruz.

İlk transformatör bloğuna bir sözcük göndermek, onun gömülmesine bakmak ve konum #1 için konumsal kodlama vektörünü toplamak anlamına gelir.
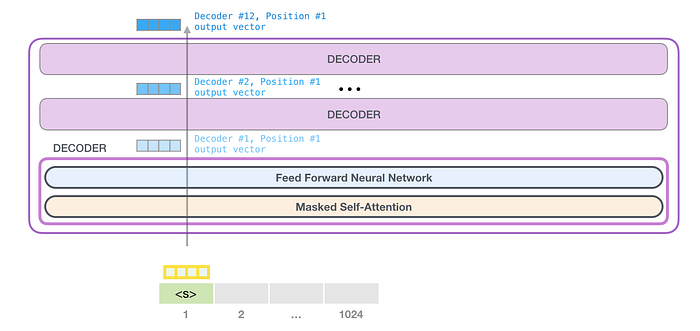
Yığına doğru bir yolculuk
İlk blok artık tokenı önce kişisel dikkat sürecinden geçirerek, ardından sinir ağı katmanından geçirerek işleyebilir. İlk transformatör bloğu tokenı işlediğinde, elde ettiği vektörü bir sonraki blok tarafından işlenmek üzere yığının yukarısına gönderir. Süreç her blokta aynıdır ancak her bloğun hem kişisel dikkat hem de sinir ağı alt katmanlarında kendi ağırlıkları vardır.
Kişisel Dikkat Özeti
Dil büyük ölçüde bağlama dayanır. Örneğin ikinci yasaya bakın:
Robotiğin İkinci Yasası Bir robot, Birinci Yasa ile çelişen emirler dışında, insanlar tarafından kendisine verilen emirlere uymak zorundadır .
Cümlede kelimelerin başka kelimelere gönderme yaptığı üç yeri vurguladım. Bu kelimeleri, atıfta bulundukları bağlamı dahil etmeden anlamanın veya işlemenin hiçbir yolu yoktur. Bir model bu cümleyi işlerken şunları bilmelidir:
- robotu kastediyor
- bu tür emirler kanunun daha önceki kısmına, yani “insanlar tarafından verilen emirlere” atıfta bulunmaktadır.
- Birinci Yasa Birinci Yasanın tamamını ifade eder
Kişisel dikkatin yaptığı budur. Belirli bir kelimenin bağlamını açıklayan ilgili ve ilişkili kelimelerin, o kelimeyi işlemeden (bir sinir ağından geçirmeden) önce modelin anlaşılmasını sağlar. Bunu, segmentteki her kelimenin ne kadar alakalı olduğuna puanlar atayarak ve bunların vektör temsillerini toplayarak yapar.
Örnek olarak üst bloktaki bu öz-dikkat katmanı, “o” kelimesini işlerken “bir robot”a dikkat ediyor. Sinir ağına ileteceği vektör, üç kelimenin her biri için vektörlerin puanlarıyla çarpımının toplamıdır.
Kişisel Dikkat Süreci
Kişisel dikkat, segmentteki her bir tokenın yolu boyunca işlenir. Önemli bileşenler üç vektördür:
- Sorgu : Sorgu, diğer tüm kelimelere (anahtarlarını kullanarak) karşı puanlama yapmak için kullanılan mevcut kelimenin bir temsilidir. Yalnızca şu anda işlemekte olduğumuz tokenın sorgusuyla ilgileniyoruz.
- Anahtar : Anahtar vektörler segmentteki tüm kelimelerin etiketleri gibidir. İlgili kelimeleri ararken eşleştirdiğimiz şeyler bunlardır.
- Değer : Değer vektörleri gerçek kelime temsilleridir; her kelimenin ne kadar alakalı olduğunu puanladığımızda bunlar, mevcut kelimeyi temsil etmek için topladığımız değerlerdir.
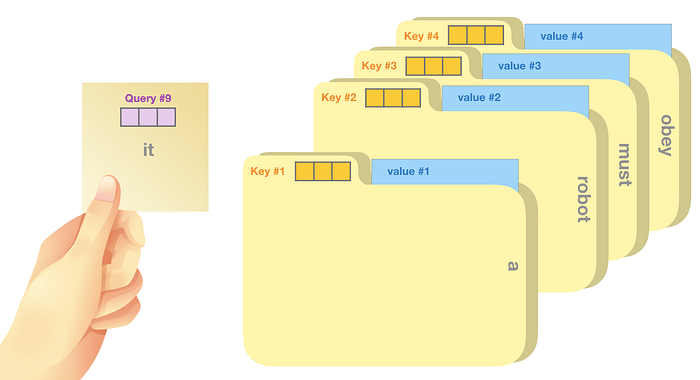
Kaba bir benzetme, bunu bir dosya dolabını karıştırmak gibi düşünmektir. Sorgu, araştırdığınız konuyla ilgili yapışkan bir not gibidir. Anahtarlar dolabın içindeki klasörlerin etiketleri gibidir. Etiketi yapışkan notla eşleştirdiğinizde o klasörün içeriğini çıkarıyoruz, bu içerikler değer vektörüdür. Ancak yalnızca tek bir değer aramıyorsunuz, aynı zamanda klasörlerin karışımından değerlerin bir karışımını arıyorsunuz.
Sorgu vektörünün her anahtar vektörle çarpılması, her klasör için bir puan üretir (teknik olarak: nokta çarpımı ve ardından softmax gelir).
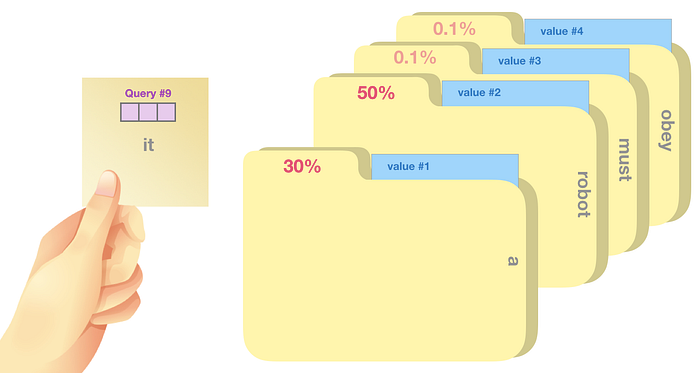
Her değeri puanıyla çarparız ve toplarız; sonuçta öz dikkat sonucumuz ortaya çıkar.
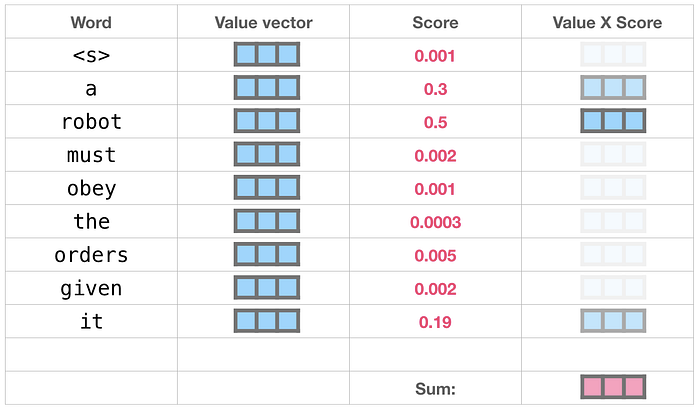
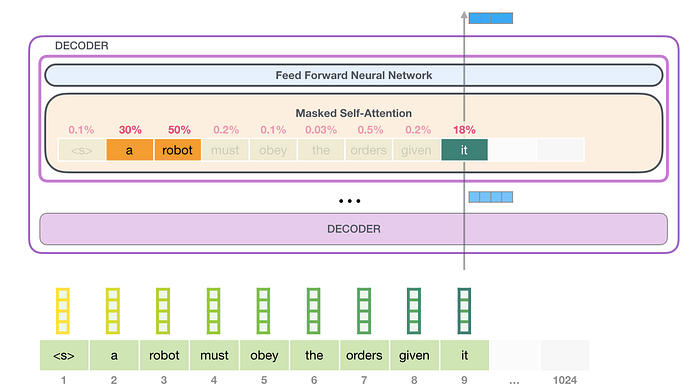
Değer vektörlerinin bu ağırlıklı karışımı, “dikkatinin” %50'sini kelimeye robot, %30'unu kelimeye ave %19'unu kelimeye ödeyen bir vektörle sonuçlanır it. Yazının ilerleyen kısımlarında kişisel dikkat konusunu daha da derinleştireceğiz. Ama önce modelin çıktısına doğru yığının yukarısına doğru yolculuğumuza devam edelim.
Model Çıkışı
Modeldeki üst blok kendi çıktı vektörünü ürettiğinde (kendi dikkatinin ve ardından kendi sinir ağının sonucu), model bu vektörü yerleştirme matrisiyle çarpar.

Gömme matrisindeki her satırın, modelin sözlüğündeki bir kelimenin gömülmesine karşılık geldiğini hatırlayın. Bu çarpmanın sonucu, modelin sözlüğündeki her kelime için bir puan olarak yorumlanır.

En yüksek puana sahip tokenı kolayca seçebiliriz (top_k = 1). Ancak modelin diğer kelimeleri de dikkate alması durumunda daha iyi sonuçlar elde edilir. Bu nedenle daha iyi bir strateji, puanı o kelimenin seçilme olasılığı olarak kullanarak tüm listeden bir kelimeyi örneklemektir (bu nedenle daha yüksek puana sahip kelimelerin seçilme şansı daha yüksektir). Orta yol, top_k’yi 40'a ayarlamak ve modelin en yüksek puanlara sahip 40 kelimeyi dikkate almasını sağlamaktır.

Bununla birlikte model, tek bir kelimenin çıktısıyla sonuçlanan bir yinelemeyi tamamladı. Model, bağlamın tamamı oluşturulana kadar (1024 token) veya bir dizi sonu tokenı üretilene kadar yinelemeye devam eder.
1. bölümün sonu: Bayanlar ve Baylar GPT-2
Ve işte buradayız. GPT2'nin nasıl çalıştığına dair kısa bir özet yaptık. Öz-dikkat katmanının içinde tam olarak ne olduğunu merak ediyorsanız aşağıdaki bonus bölümü tam size göre. Daha sonraki transformatör modellerinin incelenmesini ve tanımlanmasını kolaylaştırmak amacıyla, kişisel dikkati tanımlamak için daha fazla görsel dil sunmak amacıyla bunu oluşturdum (size bakarken, TransformerXL ve XLNet).
Bu yazıda birkaç aşırı basitleştirmeye dikkat çekmek istiyorum:
- “Kelimeler” ve “belirteçler”i birbirinin yerine kullandım. Ancak gerçekte GPT2, sözlüğündeki belirteçleri oluşturmak için Bayt Çifti Kodlamasını kullanır. Bu, belirteçlerin genellikle kelimelerin parçaları olduğu anlamına gelir.
- Gösterdiğimiz örnek, GPT2'yi çıkarım/değerlendirme modunda çalıştırıyor. Bu yüzden aynı anda yalnızca bir kelimeyi işliyor. Eğitim sırasında model, daha uzun metin dizilerine ve birden fazla tokenın aynı anda işlenmesine karşı eğitilecektir. Ayrıca eğitim sırasında model, değerlendirmenin kullandığı toplu iş boyutuna kıyasla daha büyük toplu iş boyutlarını (512) işleyecektir.
- Görüntülerdeki boşlukları daha iyi yönetmek için vektörleri döndürme/transpoze etme konusunda özgür davrandım. Uygulama zamanında daha kesin olmak gerekir.
- Transformatörler çok fazla katman normalleştirmesi kullanır ve bu oldukça önemlidir. Bunlardan birkaçını Illustrated Transformer’da not ettik, ancak bu yazıda daha çok kişisel dikkat üzerine odaklandık.
- Bir vektörü temsil etmek için daha fazla kutu göstermem gereken zamanlar var. Bunları “yakınlaştırmak” olarak belirtiyorum. Örneğin:
Bölüm #2: Resimli Kişisel Dikkat
Gönderinin başlarında, bu görseli, kelimeyi işleyen bir katmanda uygulanan öz dikkati sergilemek için göstermiştik it:

Bu bölümde bunun nasıl yapıldığına dair ayrıntılara bakacağız. Tek tek kelimelere ne olduğunu anlamaya çalışacak şekilde bakacağımızı unutmayın. Bu yüzden birçok tek vektör göstereceğiz. Gerçek uygulamalar dev matrislerin birbiriyle çarpılmasıyla yapılır. Ancak burada kelime düzeyinde olup bitenlerin sezgisine odaklanmak istiyorum.
Kişisel Dikkat (maskelemeden)
Bir kodlayıcı blokta hesaplanan orijinal kişisel dikkat durumuna bakarak başlayalım. Aynı anda yalnızca dört tokenı işleyebilen oyuncak transformatör bloğuna bakalım.
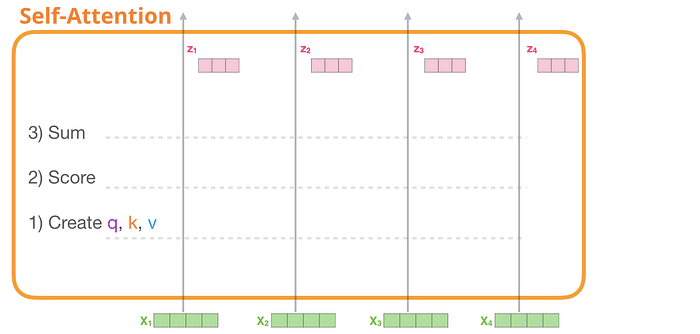
Kişisel dikkat üç ana adımla uygulanır:
- Her yol için Sorgu, Anahtar ve Değer vektörlerini oluşturun.
- Her giriş tokenı için, diğer tüm anahtar vektörlere göre puan almak üzere sorgu vektörünü kullanın
- Değer vektörlerini ilgili puanlarla çarparak toplayın.

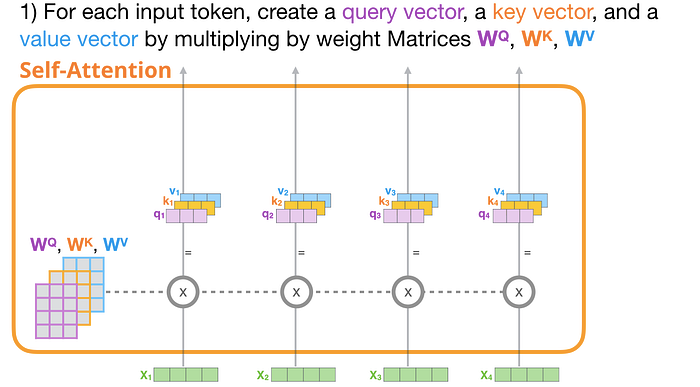
1- Sorgu, Anahtar ve Değer Vektörleri Oluşturun
İlk yola odaklanalım. Sorgusunu alıp tüm anahtarlarla karşılaştıracağız. Bu, her anahtar için bir puan üretir. Kişisel dikkatin ilk adımı, her simge yolu için üç vektörü hesaplamaktır (şimdilik dikkat başlıklarını göz ardı edelim):
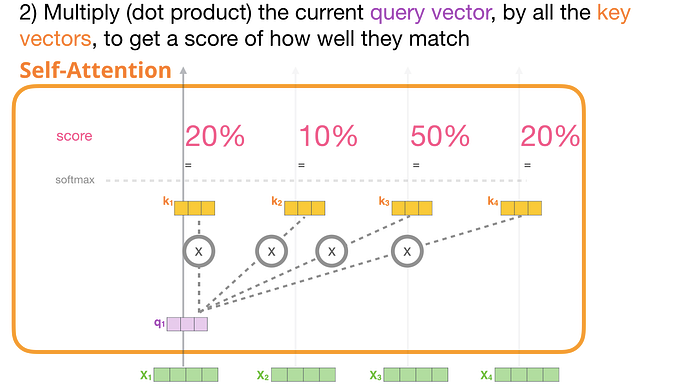
2- Skor
Artık vektörlere sahip olduğumuza göre sorgu ve anahtar vektörlerini yalnızca 2. adım için kullanıyoruz. İlk tokena odaklandığımız için sorgusunu diğer tüm anahtar vektörlerle çarparak dört tokenin her biri için bir puan elde ederiz.
3- Toplam
Artık puanları değer vektörleriyle çarpabiliriz. Puanı yüksek olan bir değer, bunları topladığımızda ortaya çıkan vektörün büyük bir kısmını oluşturacaktır.

Puan ne kadar düşük olursa değer vektörünü o kadar şeffaf gösteriyoruz. Bu, küçük bir sayıyla çarpmanın vektörün değerlerini nasıl seyrelttiğini göstermek içindir.
Her yol için aynı işlemi yaparsak, o tokenın uygun bağlamını içeren her bir tokenı temsil eden bir vektör elde ederiz. Bunlar daha sonra transformatör bloğundaki bir sonraki alt katmana (ileri beslemeli sinir ağı) sunulur:
Resimli Maskeli Öz-Dikkat
Artık bir dönüştürücünün öz-dikkat adımının içine baktığımıza göre, maskeli öz-dikkat aşamasına bakmaya geçelim. Maskelenmiş öz-dikkat, 2. adıma gelindiği durumlar hariç, öz-dikkatle aynıdır. Modelin girdi olarak yalnızca iki tokena sahip olduğunu ve ikinci tokenı gözlemlediğimizi varsayalım. Bu durumda son iki token maskelenir. Yani model puanlama adımına müdahale ediyor. Temel olarak gelecekteki tokenları her zaman 0 olarak puanlar, böylece model gelecekteki kelimelere ulaşamaz:
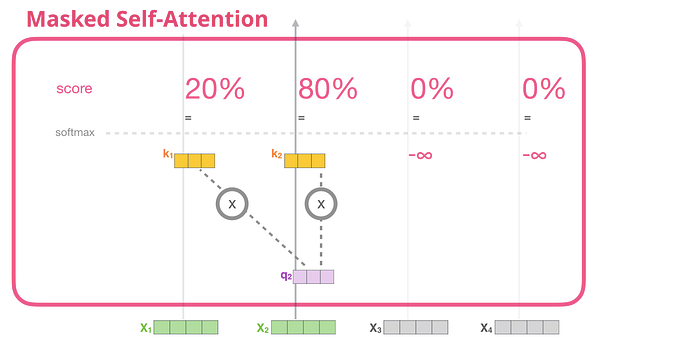
Bu maskeleme genellikle dikkat maskesi adı verilen bir matris olarak uygulanır. Dört kelimeden oluşan bir dizi düşünün (örneğin, “robot emirlere uymalıdır”). Bir dil modelleme senaryosunda bu dizi, kelime başına bir tane olmak üzere dört adımda gerçekleştirilir (şimdilik her kelimenin bir simge olduğu varsayılarak). Bu modeller gruplar halinde çalıştığından, tüm sırayı (dört adımıyla birlikte) tek bir grup olarak işleyecek bu oyuncak modeli için parti boyutunu 4 olarak kabul edebiliriz.

Matris formunda, sorgu matrisini anahtar matrisiyle çarparak puanları hesaplarız. Bunu şu şekilde görselleştirelim, ancak o hücrede kelime yerine o kelimeyle ilişkili sorgu (veya anahtar) vektörü olacaktır:

Çarpma işleminden sonra dikkat maskesi üçgenimize tokat atıyoruz. Maskelemek istediğimiz hücreleri -sonsuza veya çok büyük bir negatif sayıya (örneğin, GPT2'de -1 milyar) ayarlar:

Daha sonra, her satıra softmax uygulamak, kişisel dikkat için kullandığımız gerçek puanları üretir:
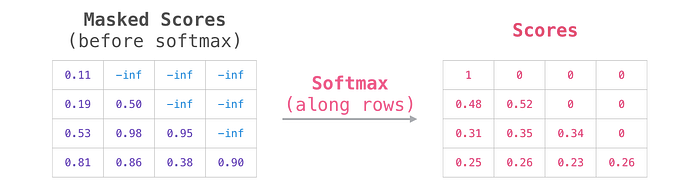
Bu puan tablosunun anlamı şudur:
- Model, yalnızca bir kelime (“robot”) içeren veri kümesindeki ilk örneği (satır #1) işlediğinde, dikkatinin %100'ü o kelime üzerinde olacaktır.
- Model, veri kümesindeki (“robot gerekir”) sözcüklerini içeren ikinci örneği (satır #2) işlediğinde, “zorunluluk” sözcüğünü işlediğinde dikkatinin %48'i “robot” üzerinde olacak ve 52 Dikkatinin %’si “zorunluluk” üzerinde olacaktır.
- Ve benzerleri
GPT-2 Maskelenmiş Öz-Dikkat
GPT-2'nin maskelenmiş dikkati hakkında daha fazla ayrıntıya girelim.
Değerlendirme Süresi: Tek Seferde Bir Token İşleme
GPT-2'nin tam olarak maskelenmiş öz-dikkat çalışmaları gibi çalışmasını sağlayabiliriz. Ancak değerlendirme sırasında, modelimiz her yinelemeden sonra yalnızca bir yeni kelime eklediğinde, halihazırda işlenmiş belirteçler için önceki yollar boyunca öz dikkati yeniden hesaplamak verimsiz olacaktır.
Bu durumda ilk tokenı işliyoruz ( <s>şimdilik görmezden geliyoruz).

GPT-2, tokenın anahtar ve değer vektörlerini tutar a. Her kişisel dikkat katmanı, o simgeye ilişkin ilgili anahtar ve değer vektörlerine tutunur:
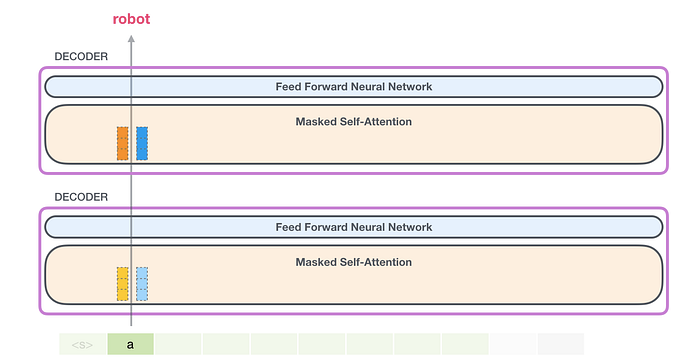
Şimdi bir sonraki yinelemede model sözcüğü işlediğinde robot, belirteç için sorgu, anahtar ve değer sorguları üretmesine gerek yoktur a. Yalnızca ilk yinelemeden kaydettiklerini yeniden kullanır:

GPT-2 Kişisel Dikkat: 1- Sorgular, anahtarlar ve değerler oluşturma
Modelin kelimeyi işlediğini varsayalım it. Eğer alt bloktan bahsediyorsak, bu tokenin girişi it+ 9 numaralı slot için konumsal kodlamanın yerleştirilmesi olacaktır:

Bir transformatördeki her bloğun kendi ağırlıkları vardır (daha sonra yazıda açıklanmıştır). İlk karşılaştığımız sorguları, anahtarları ve değerleri oluşturmak için kullandığımız ağırlık matrisidir.

Kişisel dikkat, girdisini ağırlık matrisiyle çarpar (ve burada gösterilmeyen bir önyargı vektörü ekler).
Çarpma işlemi, temel olarak sözcüğün sorgu, anahtar ve değer vektörlerinin birleşiminden oluşan bir vektörle sonuçlanır it.
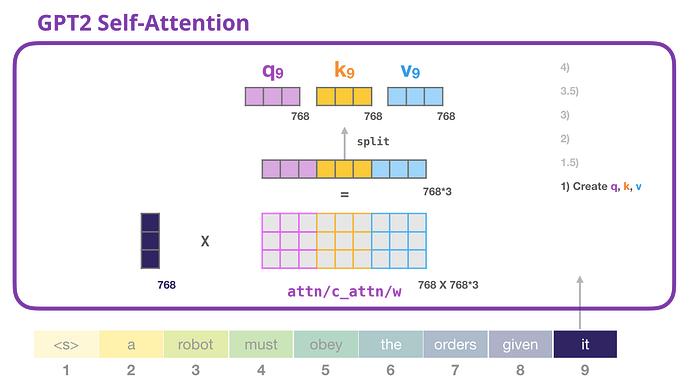
Giriş vektörünü dikkat ağırlıkları vektörüyle çarpmak (ve sonrasında bir önyargı vektörü eklemek), bu belirteç için anahtar, değer ve sorgu vektörleriyle sonuçlanır.
GPT-2 Öz-dikkat: 1.5- Dikkat kafalarına bölünme
Önceki örneklerde, “çok kafalı” kısmı göz ardı ederek doğrudan kişisel dikkat konusuna daldık. Şimdi bu kavrama biraz ışık tutmakta fayda var. Kişisel dikkat, Q,K,V vektörlerinin farklı kısımlarında birçok kez gerçekleştirilir. Dikkat kafalarını “bölmek”, uzun vektörü bir matris halinde yeniden şekillendirmektir. Küçük GPT2'nin 12 dikkat kafası vardır, dolayısıyla bu, yeniden şekillendirilen matrisin ilk boyutu olacaktır:
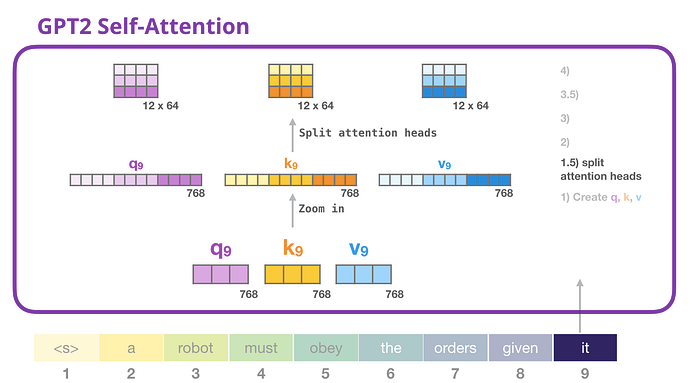
Önceki örneklerde bir dikkat kafasının içinde neler olduğuna baktık. Birden fazla dikkat kafasını düşünmenin bir yolu şu şekildedir (eğer on iki dikkat kafasından yalnızca üçünü görselleştireceksek):

GPT-2 Kişisel Dikkat: 2- Puanlama
Artık yalnızca tek bir dikkat noktasına baktığımızı (ve diğerlerinin de benzer bir işlemi yürüttüğünü bilerek) puanlamaya geçebiliriz:
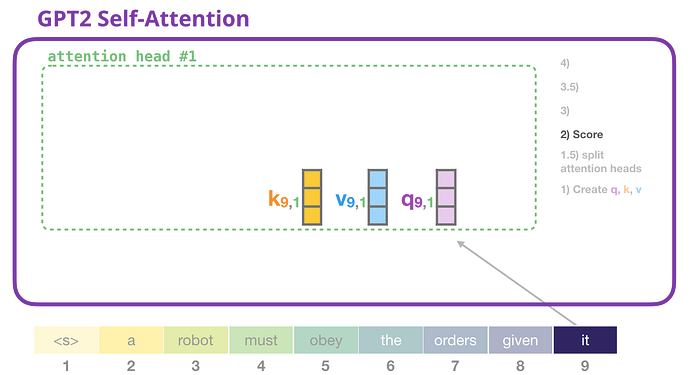
Artık token, diğer tokenların tüm anahtarlarına göre puanlanabilir (önceki yinelemelerde dikkat #1'de hesaplanmıştır):

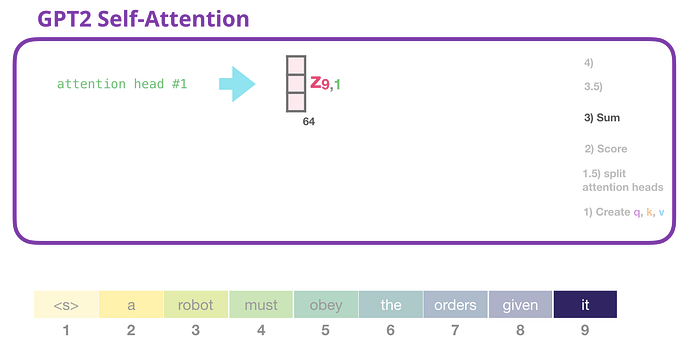
GPT-2 Kendine Dikkat: 3- Toplam
Daha önce gördüğümüz gibi, şimdi her değeri puanıyla çarpıyoruz, sonra bunları toplayarak 1 numaralı dikkat kafası için öz-dikkat sonucunu üretiyoruz:
GPT-2 Kişisel Dikkat: 3.5- Dikkat başlıklarını birleştirme
Çeşitli dikkat başlıklarıyla baş etme yöntemimiz, öncelikle onları tek bir vektörde birleştirmektir:
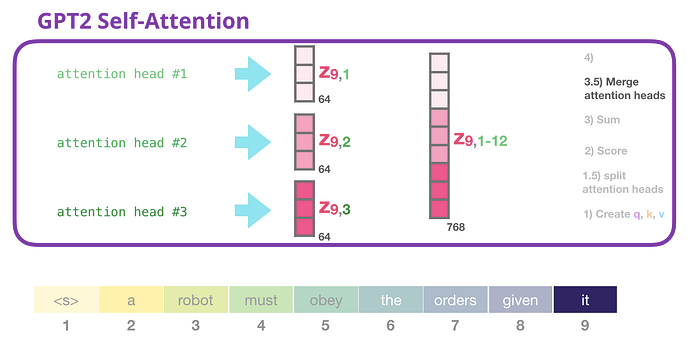
Ancak vektör henüz bir sonraki alt katmana gönderilmeye hazır değil. Öncelikle Frankenstein’ın bu gizli durumlar canavarını homojen bir temsile dönüştürmemiz gerekiyor.
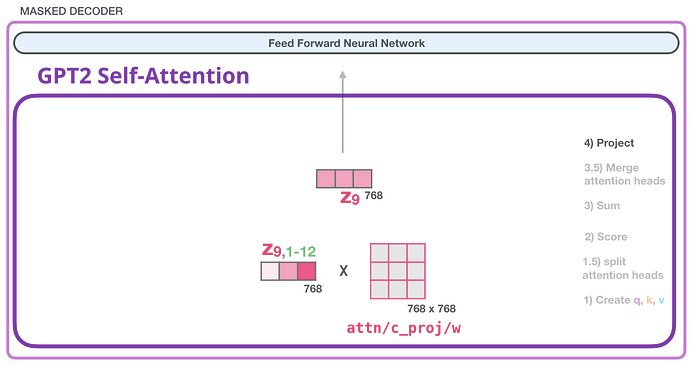
GPT-2 Öz-dikkat: 4- Yansıtma
Modelin, birleştirilmiş öz dikkat sonuçlarını ileri beslemeli sinir ağının başa çıkabileceği bir vektöre en iyi şekilde nasıl eşleştireceğini öğrenmesine izin vereceğiz. Dikkat kafalarının sonuçlarını kişisel dikkat alt katmanının çıktı vektörüne yansıtan ikinci büyük ağırlık matrisimiz geliyor:

Ve bununla bir sonraki katmana gönderebileceğimiz vektörü ürettik:
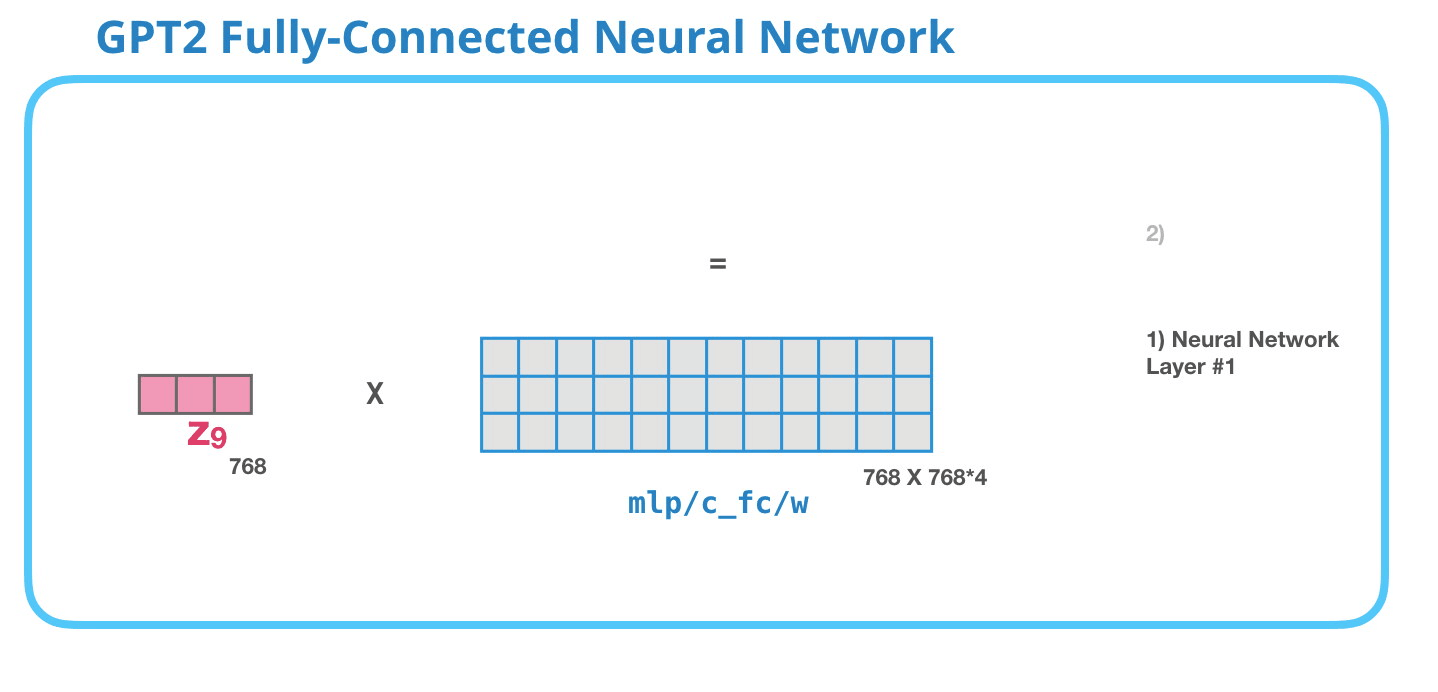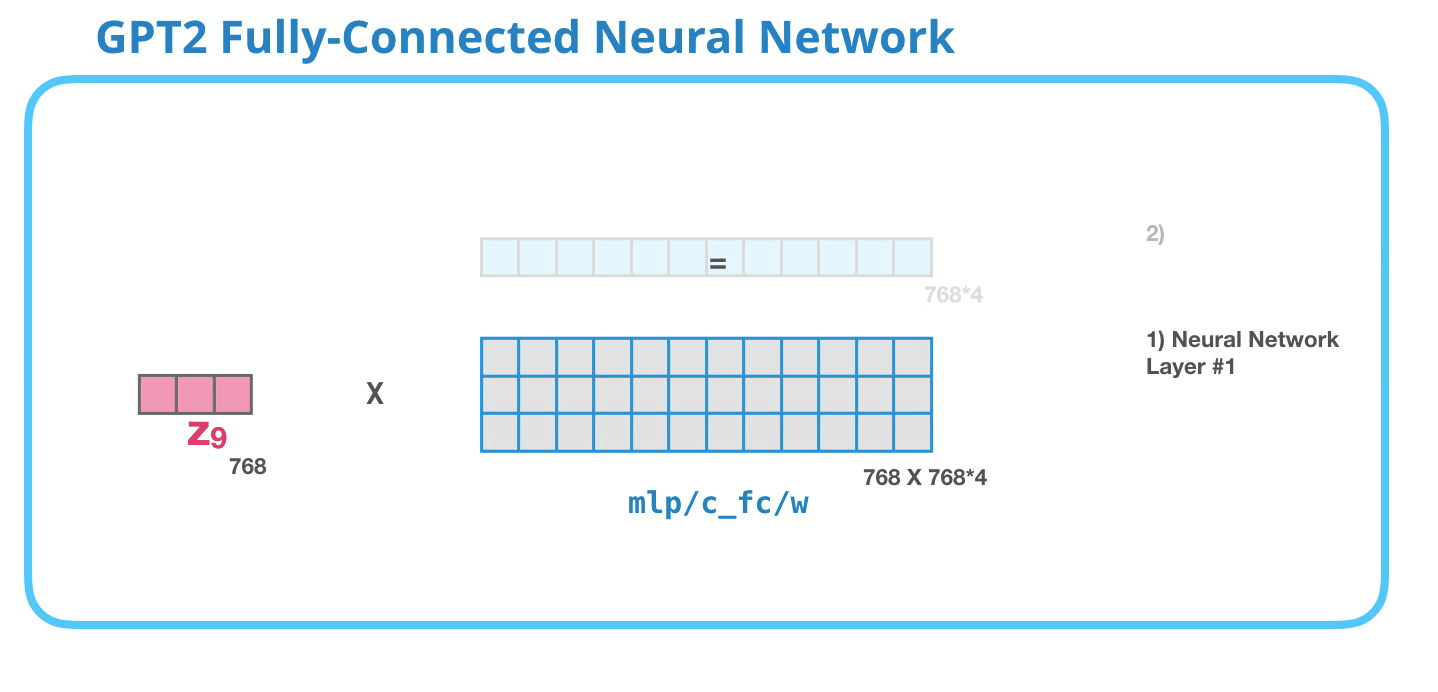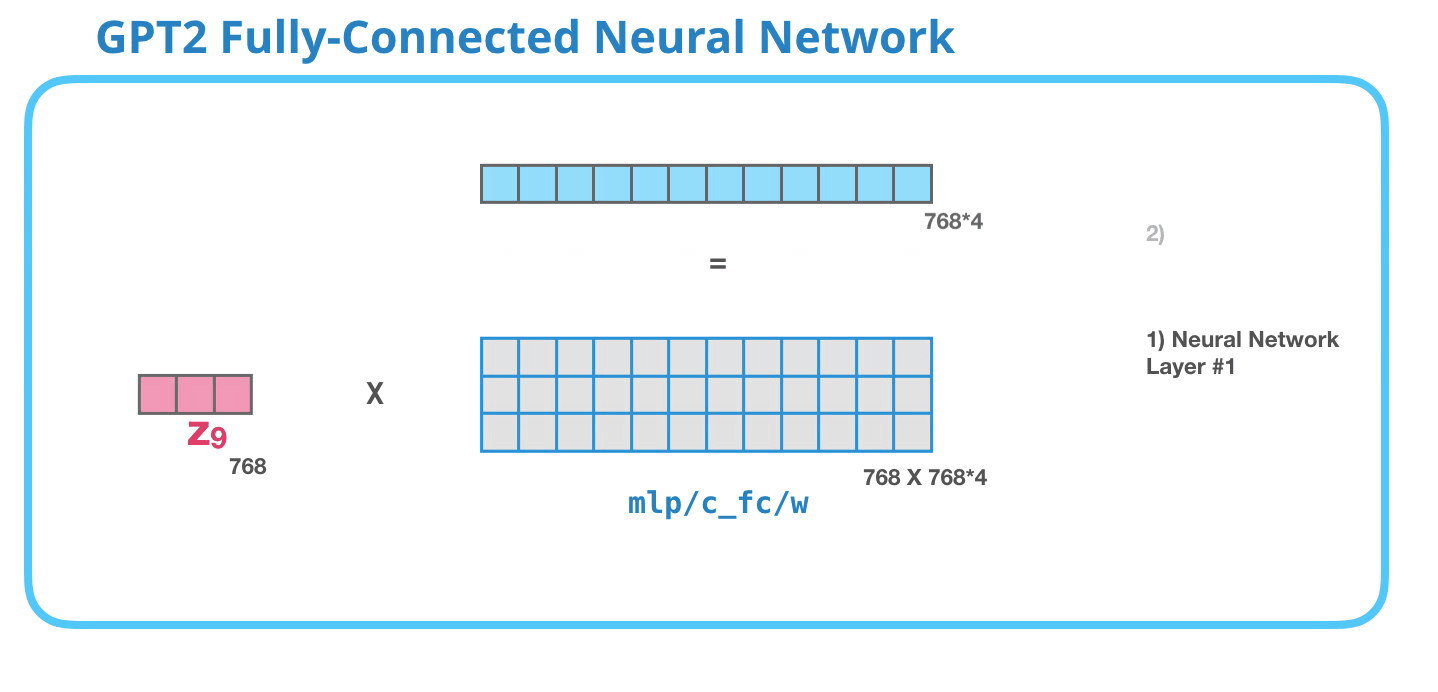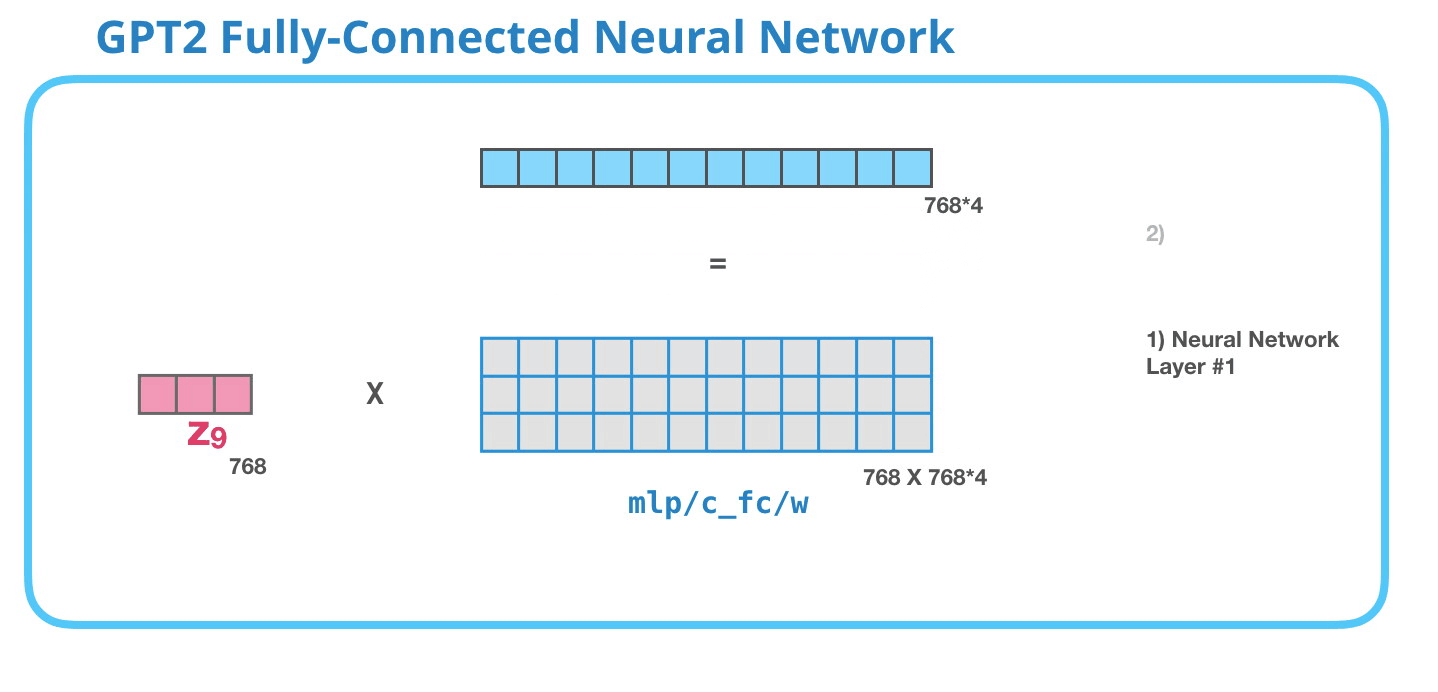
GPT-2 Tamamen Bağlantılı Sinir Ağı: Katman #1
Tamamen bağlı sinir ağı, bloğun, kişisel dikkatin temsiline uygun bağlamı dahil etmesinden sonra giriş tokenını işlediği yerdir. İki katmandan oluşur. İlk katman modelin dört katı büyüklüğündedir (GPT2 küçük 768 olduğundan bu ağda 768*4 = 3072 birim olacaktır). Neden dört kez? Bu sadece orijinal transformatörün yuvarlandığı boyuttur (model boyutu 512'ydi ve bu modeldeki 1. katman 2048'di). Bu, transformatör modellerine şu ana kadar kendilerine verilen görevleri yerine getirebilecek yeterli temsil kapasitesini sağlıyor gibi görünüyor.
GPT-2 Tam Bağlantılı Sinir Ağı: Katman #2 Model boyutuna yansıtma
İkinci katman, birinci katmanın sonucunu model boyutuna (küçük GPT2 için 768) geri yansıtır. Bu çarpmanın sonucu, bu tokenin transformatör bloğunun sonucudur.
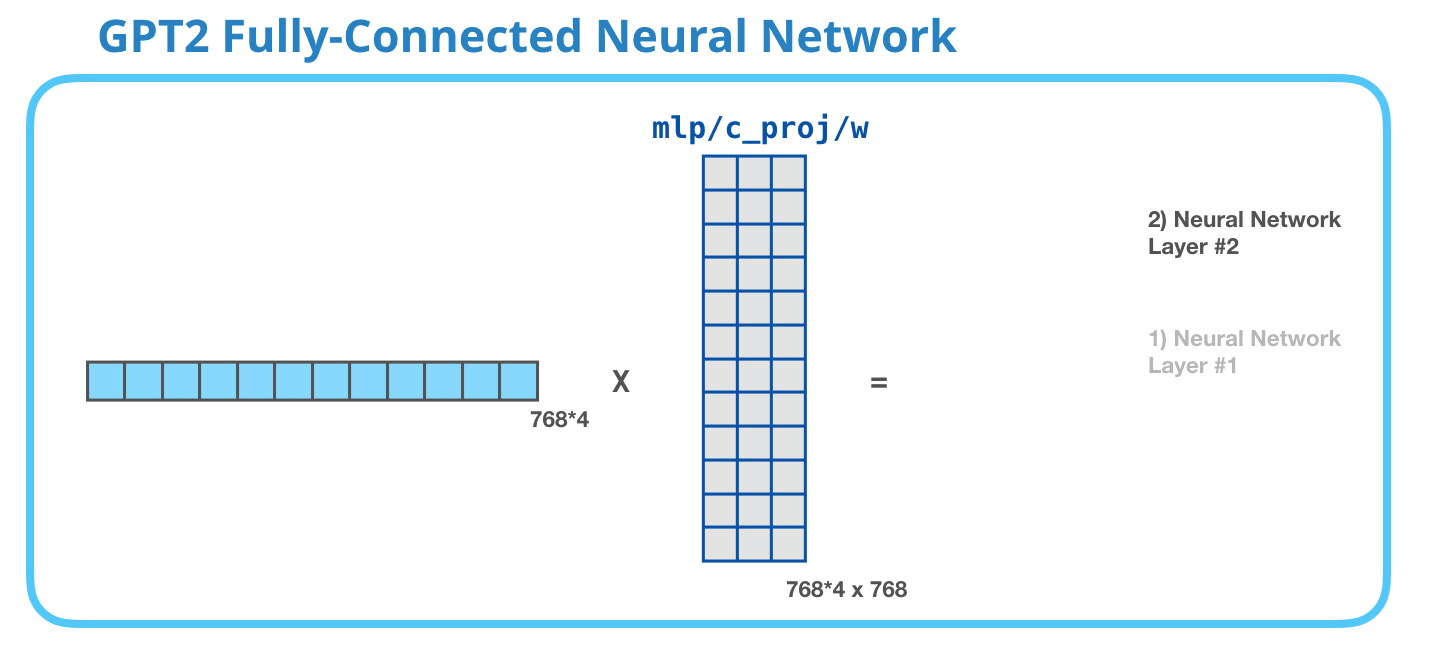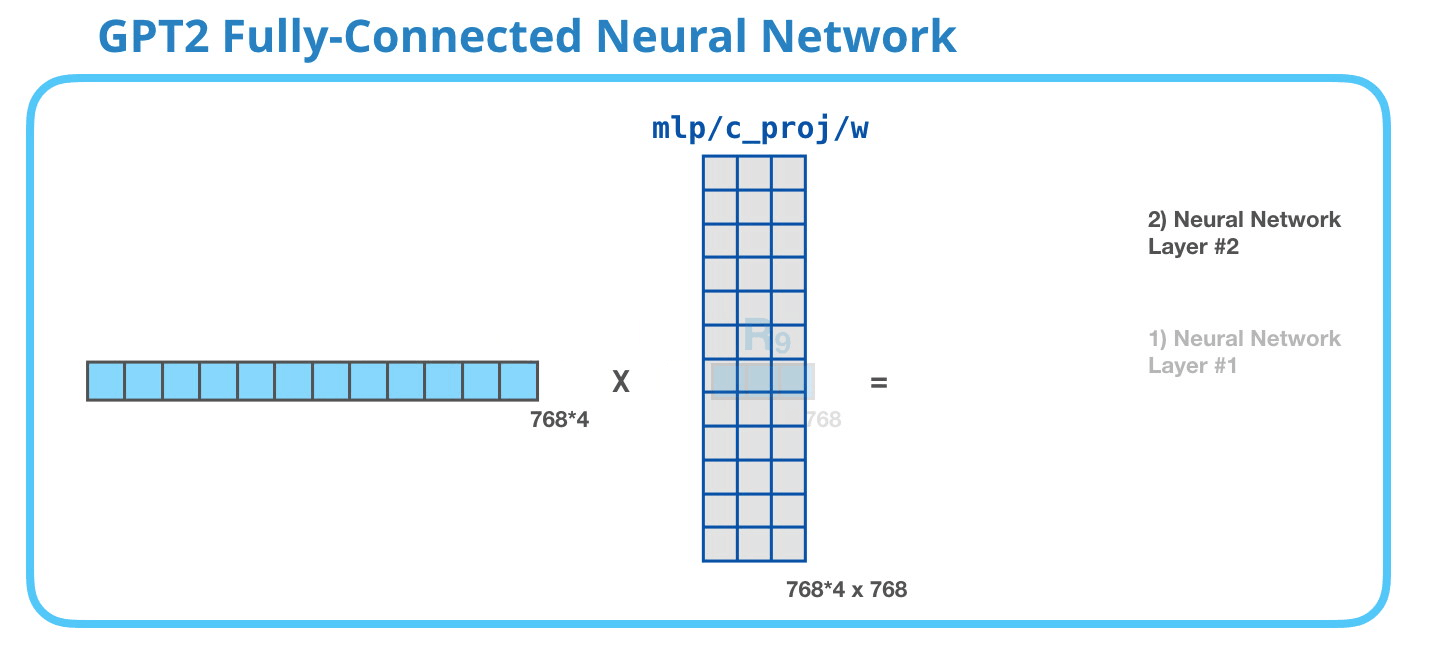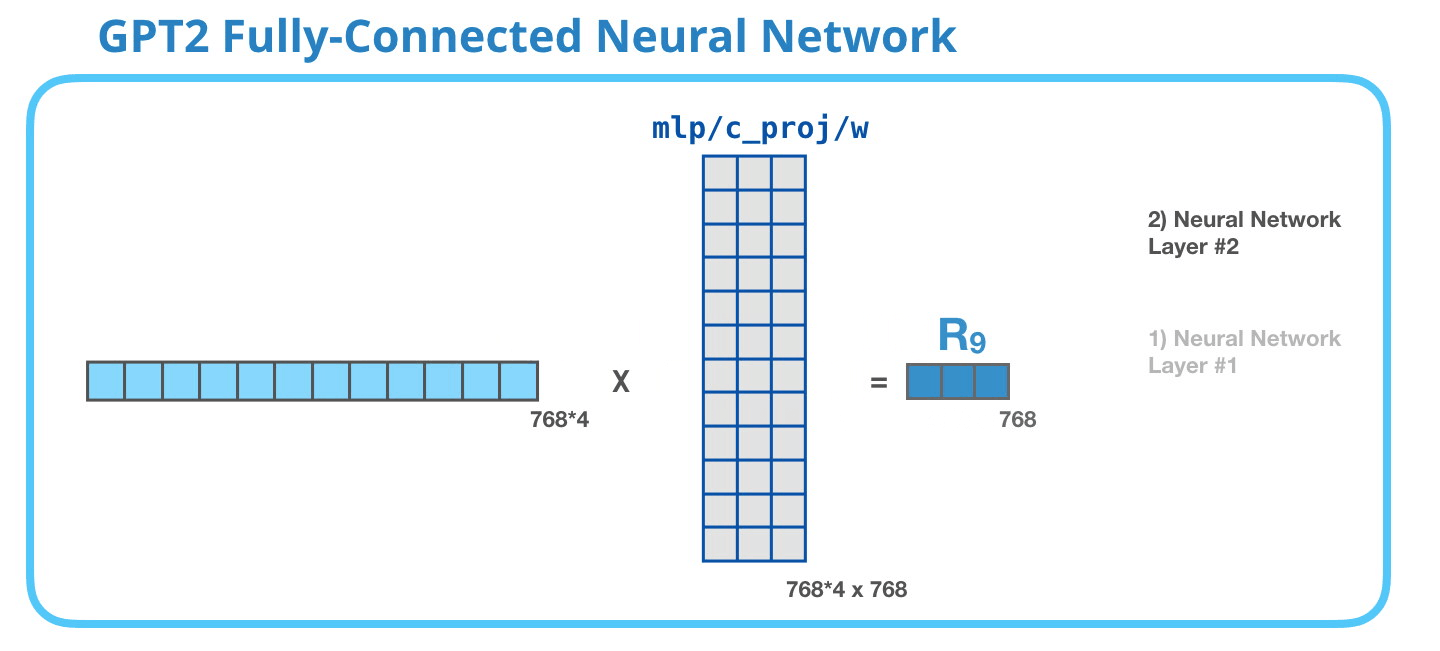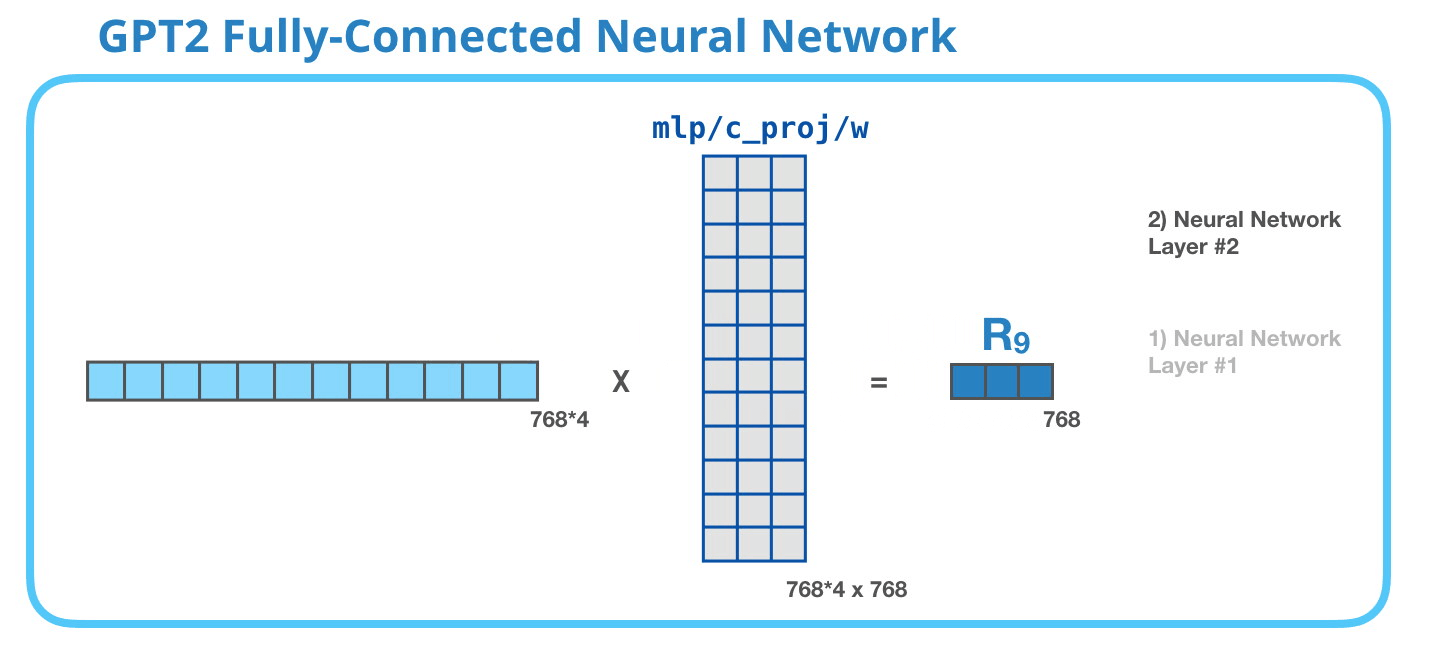
Başardın !
Bu, ele alacağımız transformatör bloğunun en ayrıntılı versiyonu! Artık bir dönüştürücü dil modelinin içinde neler olduğuna dair resmin büyük çoğunluğuna sahipsiniz. Özetlemek gerekirse, cesur girdi vektörümüz şu ağırlık matrisleriyle karşılaşır:
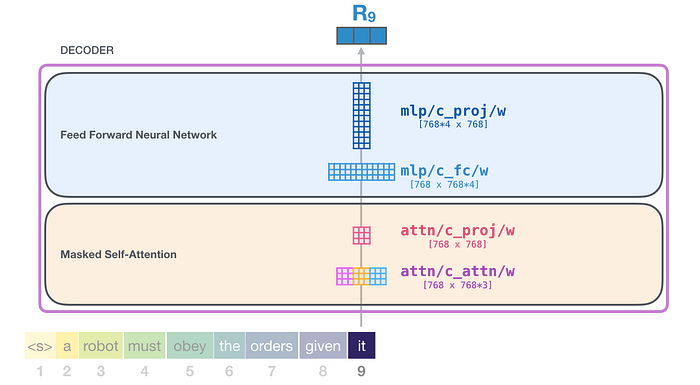
Ve her bloğun bu ağırlıklardan oluşan kendi seti vardır. Öte yandan, model yalnızca bir token yerleştirme matrisine ve bir konumsal kodlama matrisine sahiptir:
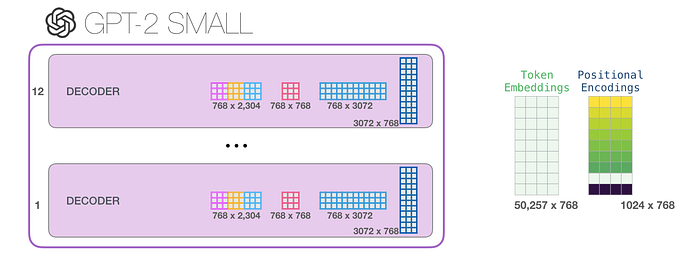
Modelin tüm parametrelerini görmek istiyorsanız bunları burada sıraladım:
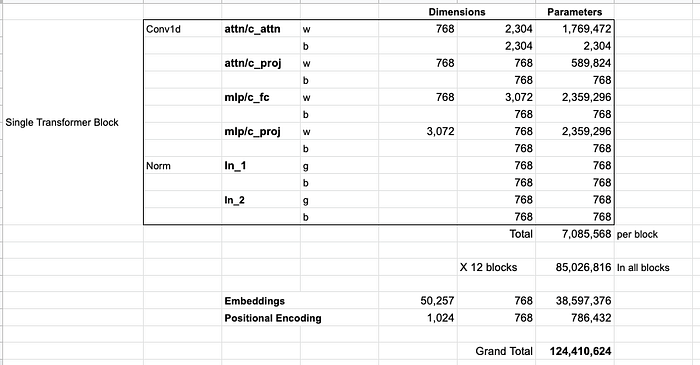
Nedense 117M yerine 124M kadar parametre ekliyorlar. Neden olduğundan emin değilim, ancak yayınlanan kodda bunlardan kaçının olduğu görülüyor (lütfen yanılıyorsam beni düzeltin).
Bölüm 3: Dil Modellemesinin Ötesinde
Yalnızca kod çözücü transformatörü, dil modellemenin ötesinde umut vaat etmeye devam ediyor. Yukarıdakilere benzer görsellerle anlatılabilecek pek çok başarı gösterdiği uygulama mevcut. Bu uygulamalardan bazılarına göz atarak bu yazıyı kapatalım.
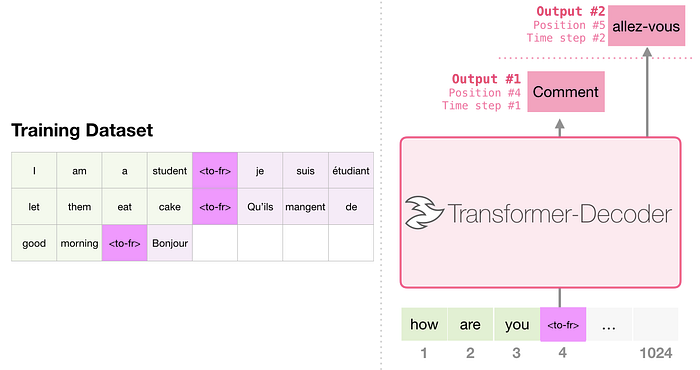
Makine Çevirisi
Çeviriyi gerçekleştirmek için kodlayıcıya gerek yoktur. Aynı görev yalnızca kod çözücü transformatörü tarafından da gerçekleştirilebilir:
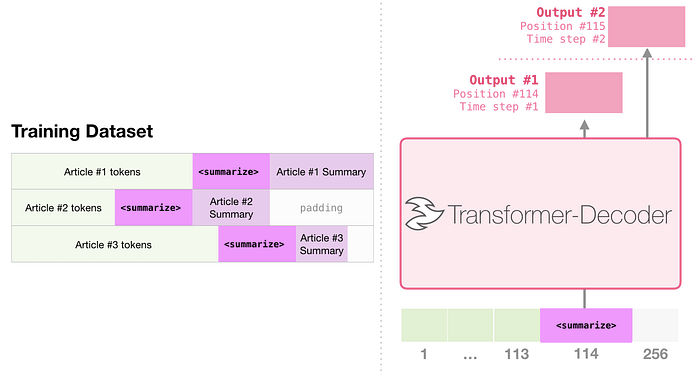
Özetleme
Bu, yalnızca kod çözücüye yönelik ilk transformatörün eğitim aldığı görevdir. Yani, bir Wikipedia makalesini okumak (içindekiler öncesindeki açılış bölümü olmadan) ve onu özetlemek üzere eğitilmişti. Makalelerin gerçek açılış bölümleri, eğitim veri kümesindeki etiketler olarak kullanıldı:

Makale, modeli wikipedia makalelerine göre eğitti ve böylece eğitilen model, makaleleri özetleyebildi:
Öğrenimi Aktar
Tek Bir Önceden Eğitimli Transformatör Kullanarak Örnek Verimli Metin Özetleme’de , yalnızca kod çözücüye yönelik bir transformatör ilk önce dil modelleme konusunda önceden eğitilir, ardından özetleme yapmak için ince ayar yapılır. Sınırlı veri ayarlarında önceden eğitilmiş bir kodlayıcı-kod çözücü transformatörden daha iyi sonuçlar elde ettiği ortaya çıktı.
GPT2 makalesi aynı zamanda modelin dil modellemesi üzerine ön eğitimi sonrasında yapılan özetleme sonuçlarını da göstermektedir.
Müzik Üretimi
Music Transformer, etkileyici zamanlama ve dinamiklere sahip müzik üretmek için yalnızca kod çözücüye yönelik bir transformatör kullanır. “Müzik Modelleme” tıpkı dil modelleme gibidir; modelin müziği denetimsiz bir şekilde öğrenmesine izin verin, ardından örnek çıktılar alın (daha önce “başıboş” dediğimiz şey).
Bu senaryoda müziğin nasıl temsil edildiğini merak ediyor olabilirsiniz. Dil modellemenin karakterlerin, kelimelerin veya kelimelerin parçaları olan simgelerin vektör temsilleri yoluyla yapılabileceğini unutmayın. Bir müzik performansında (şimdilik piyanoyu düşünelim), notaları ve aynı zamanda hızı (piyano tuşuna ne kadar sert basıldığının bir ölçüsü) temsil etmeliyiz.
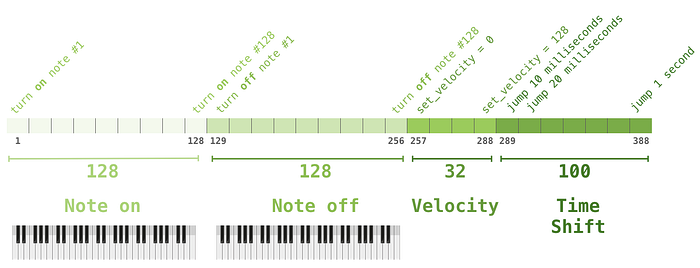
Bir performans bu tek sıcak vektörlerin yalnızca bir serisidir. Bir midi dosyası böyle bir formata dönüştürülebilir. Makalede aşağıdaki örnek giriş sırası bulunmaktadır:

Bu giriş dizisinin tek sıcak vektör gösterimi şu şekilde görünecektir:

Makalede Music Transformer’da kişisel ilgiyi gösteren bir görseli seviyorum. Buraya bazı açıklamalar ekledim:

“Şekil 8: Bu parçanın yinelenen üçgen bir konturu var. Sorgu, son zirvelerden birindedir ve parçanın başlangıcına kadar zirvedeki önceki tüm yüksek notalarla ilgilenir.” … “[Şekil] bir sorguyu (tüm dikkat çizgilerinin kaynağı) ve ilgilenilen önceki anıları (daha fazla softmax olasılığı alan notalar vurgulanmıştır) gösterir. Dikkat çizgilerinin rengi farklı kafalara karşılık gelir ve softmax olasılığının genişliğinin ağırlığına göre.”
Müzik notalarının bu temsili konusunda emin değilseniz bu videoya göz atın .
Çözüm
Bu, GPT2'ye olan yolculuğumuzu ve onun ana modeli olan yalnızca kod çözücü transformatörünü keşfetmemizi tamamlıyor. Umarım bu yazıdan, kendinize dikkat etme konusunda daha iyi bir anlayışla ve bir transformatörün içinde olup bitenleri daha iyi anladığınız için daha rahat bir şekilde çıkarsınız.
Kaynaklar
- OpenAI’den GPT2 Uygulaması
- GPT2'ye ek olarak Hugging Face’in pytorch-transformers kütüphanesine göz atın ; bu kütüphane BERT, Transformer-XL, XLNet ve diğer son teknoloji transformatör modellerini uygular.
Teşekkür
Bu yazının önceki versiyonlarına ilişkin geri bildirimleri için Lukasz Kaiser, Mathias Müller, Peter J. Liu, Ryan Sepassi and Mohammad Saleh’e teşekkür ederiz .
Referans; Jay Alammar
Alammar, J (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/
Visualizing machine learning one concept at a time.
@JayAlammar on Twitter. YouTube Channel
Devrim Danyal İrtibat & Sosyal Ağlar 📱
Akademi: https://www.devrimdanyalakademi.com
Twitter: http://twitter.com/devrimdanyal
LinkedIn: http://linkedin.com/in/devrimdanyal
YouTube: https://www.youtube.com/devrimdanyal
Instagram : https://www.instagram.com/devrimdanyal
Podcasts : https://open.spotify.com/show/6Im2GwBsAXZgysw2bIagXr
Medium: http://medium.com/@devrimdanyal
Konuşmacı Ajansları:
