Görselleştirmeler ve Animasyonlar ile GPT3 Nasıl Çalışır ?
Teknoloji dünyası GPT3 heyecanıyla çalkalanıyor. Devasa dil modelleri (GPT3 gibi) yetenekleriyle bizi şaşırtmaya başlıyor.
(Bu yazı Giriş Seviyesindeki herkesin anlayabilmesi amacıyla Jay Alammar tarafından hazırlanan How GPT3 Works — Visualizations and Animations yazısının orijinaline bağlı kalınarak düzenlenmiş çevirisidir.)
Alammar, J (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/
Çoğu işletmenin müşterilerinin önüne koyması henüz tam olarak güvenilir olmasa da, bu modeller otomasyonun ilerleyişini ve akıllı bilgisayar sistemlerinin olanaklarını kesinlikle hızlandıracak zeka kıvılcımları gösteriyor. GPT3'ün etrafındaki gizem havasını ortadan kaldıralım ve nasıl eğitildiğini ve nasıl çalıştığını öğrenelim;
Eğitilmiş bir dil modeli metin üretir.
İsteğe bağlı olarak, çıktısını etkileyen bir metni, girdi olarak iletebiliriz.
Çıktı, modelin büyük miktarda metni taradığı eğitim süresi boyunca “öğrendiği” bilgilerden üretilir.

Eğitim, modeli çok sayıda metne maruz bırakma sürecidir. O süreç tamamlandı. Şu anda gördüğünüz tüm deneyler bu eğitilmiş modelden yapılmış olup 355 GPU yılına mal olacağı ve 4,6 milyon dolara mal olacağı tahmin ediliyor.

Model için eğitim örnekleri oluşturmak amacıyla 300 milyar token eşdeğeri metinden oluşan veri kümesi kullanıldı. Örnek vermek gerekirse bunlar üstteki bir cümleden oluşturulan üç eğitim şeklindedir.
Bir pencereyi tüm metin boyunca nasıl kaydırabileceğinizi ve birçok örnek oluşturabileceğinizi görebilirsiniz.

Model bir örnekle sunulmuştur. Ona sadece özellikleri gösteriyoruz ve bir sonraki kelimeyi tahmin etmesini istiyoruz.
Modelin tahmini yanlış olacaktır. Tahminindeki hatayı hesaplıyoruz ve modeli güncelliyoruz, böylece bir dahaki sefere daha iyi bir tahmin yapsın.
Milyonlarca kez tekrarlayıp öğrenmesini güçlendiriyoruz.

Şimdi aynı adımlara biraz daha ayrıntılı olarak bakalım.
GPT3 aslında her seferinde bir token çıktı üretir (şimdilik bir tokenın bir kelime olduğunu varsayalım).

Lütfen unutmayın: Bu, GPT-3'ün nasıl çalıştığının bir açıklamasıdır ve onun hakkında yeni olanın (ki bu esas olarak gerçekten büyük ölçeklidir) tartışılması değildir. Mimari, bu makaleyi temel alan bir transformatör kod çözücü modelidir
GPT3 BÜYÜKtür. Eğitimden öğrendiklerini 175 milyar sayıyla (parametre adı verilen) kodlar. Bu sayılar, her çalıştırmada hangi tokenin üretileceğini hesaplamak için kullanılır.
Eğitimsiz model rastgele parametrelerle başlar. Eğitim, daha iyi tahminlere yol açan değerleri bulur.
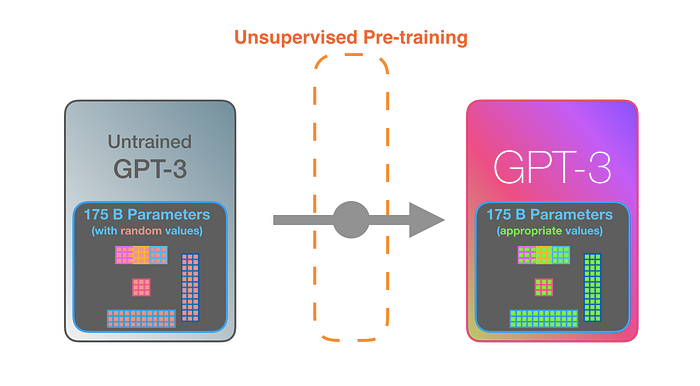
Bu sayılar modelin içindeki yüzlerce matrisin parçasıdır. Tahmin çoğunlukla çok fazla matris çarpımıdır.
YouTube’daki Yapay Zekaya Giriş’te tek parametreli basit bir makine öğrenimi modeli gösterdim. Bu 175 milyar parametreyi ortaya çıkarmak için iyi bir başlangıç.
Bu parametrelerin nasıl dağıtıldığına ve kullanıldığına ışık tutmak için modeli açıp içine bakmamız gerekecek.
GPT3 2048 token genişliğindedir. Bu onun (context window) “bağlam penceresi”dir. Bu, tokenların işlendiği 2048 parçaya sahip olduğu anlamına gelir.
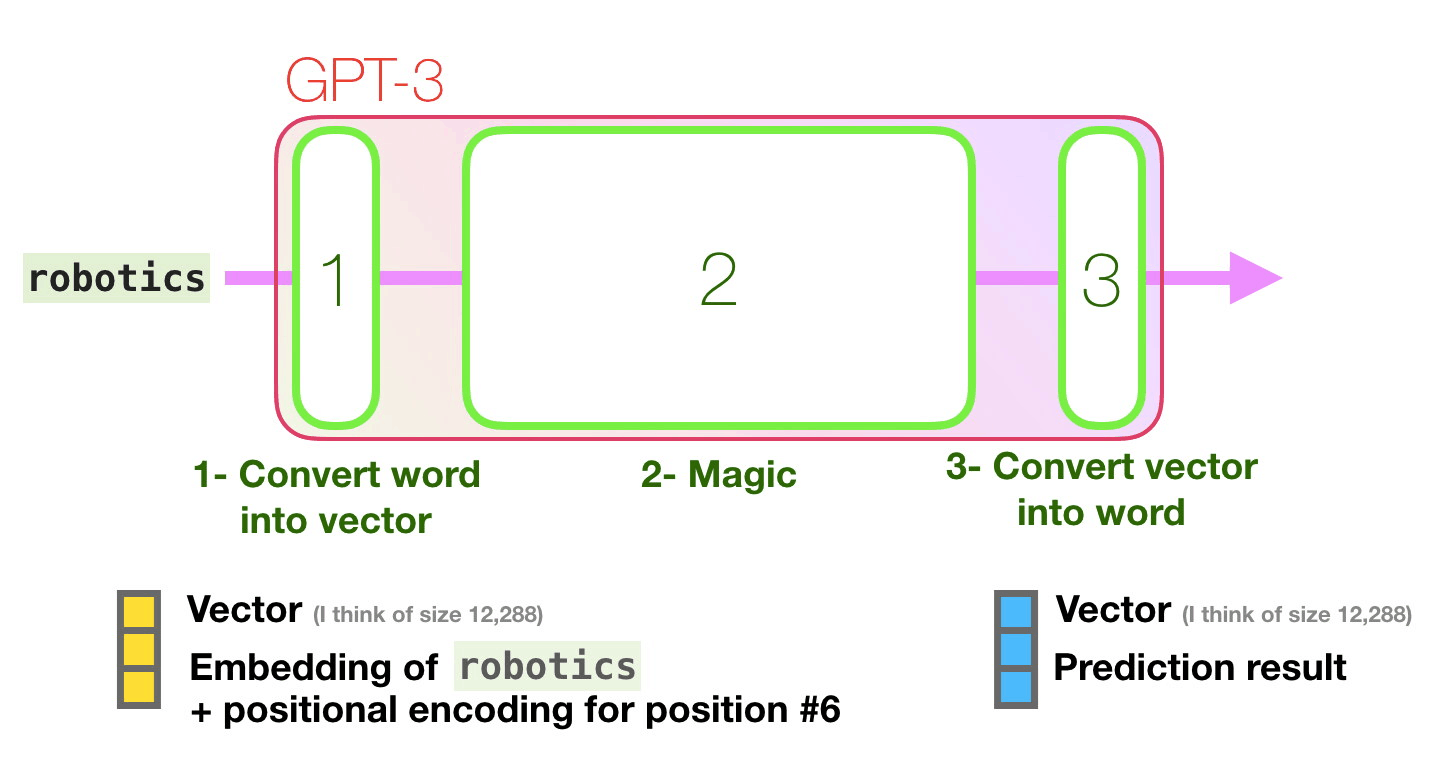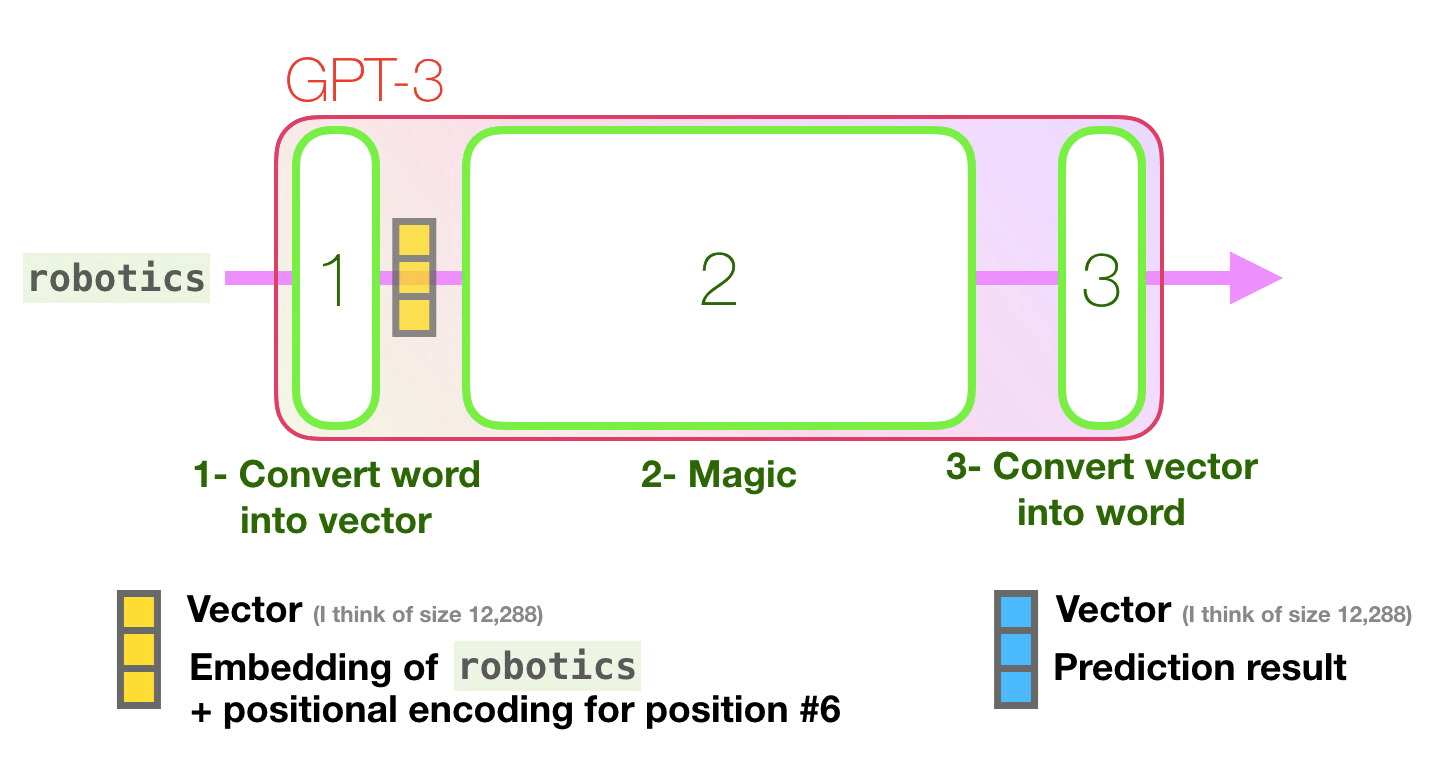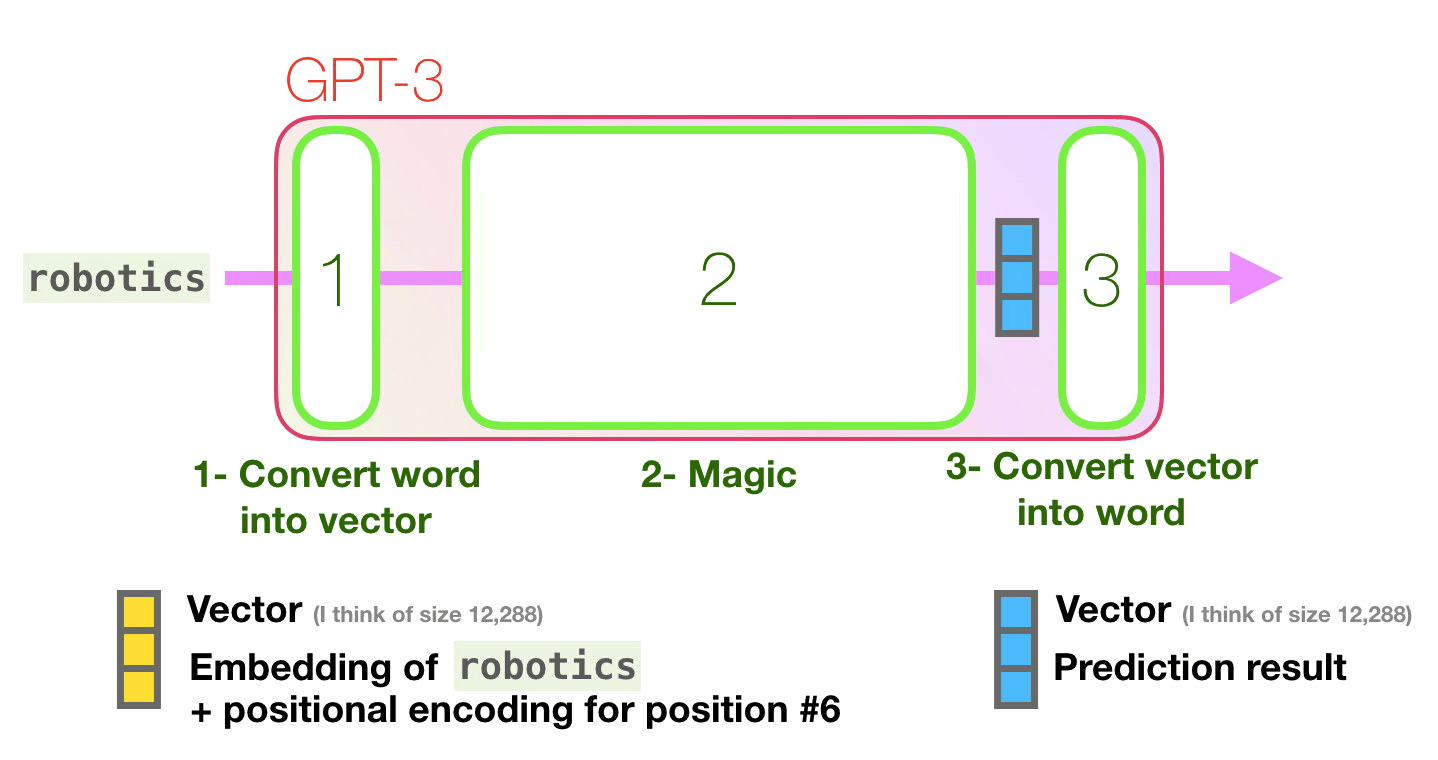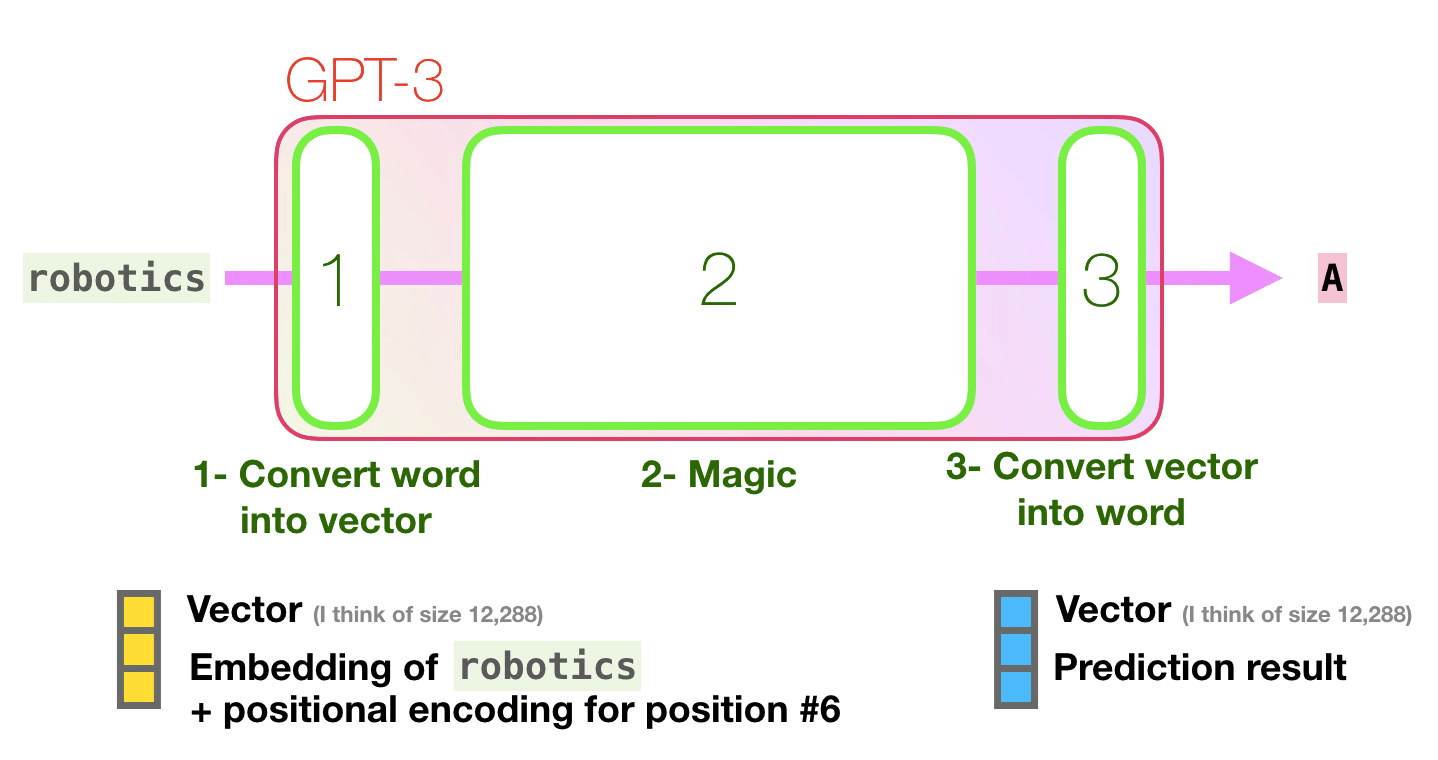
Mor yolu takip edelim. Bir sistem “robotik” kelimesini nasıl işleyerek “A”yı üretir?
Üst düzey adımlar:
- Kelimeyi, kelimeyi temsil eden bir vektöre (sayı listesi) dönüştürür
- Hesaplama tahmini yapar
- Ortaya çıkan vektörü kelimeye dönüştürür
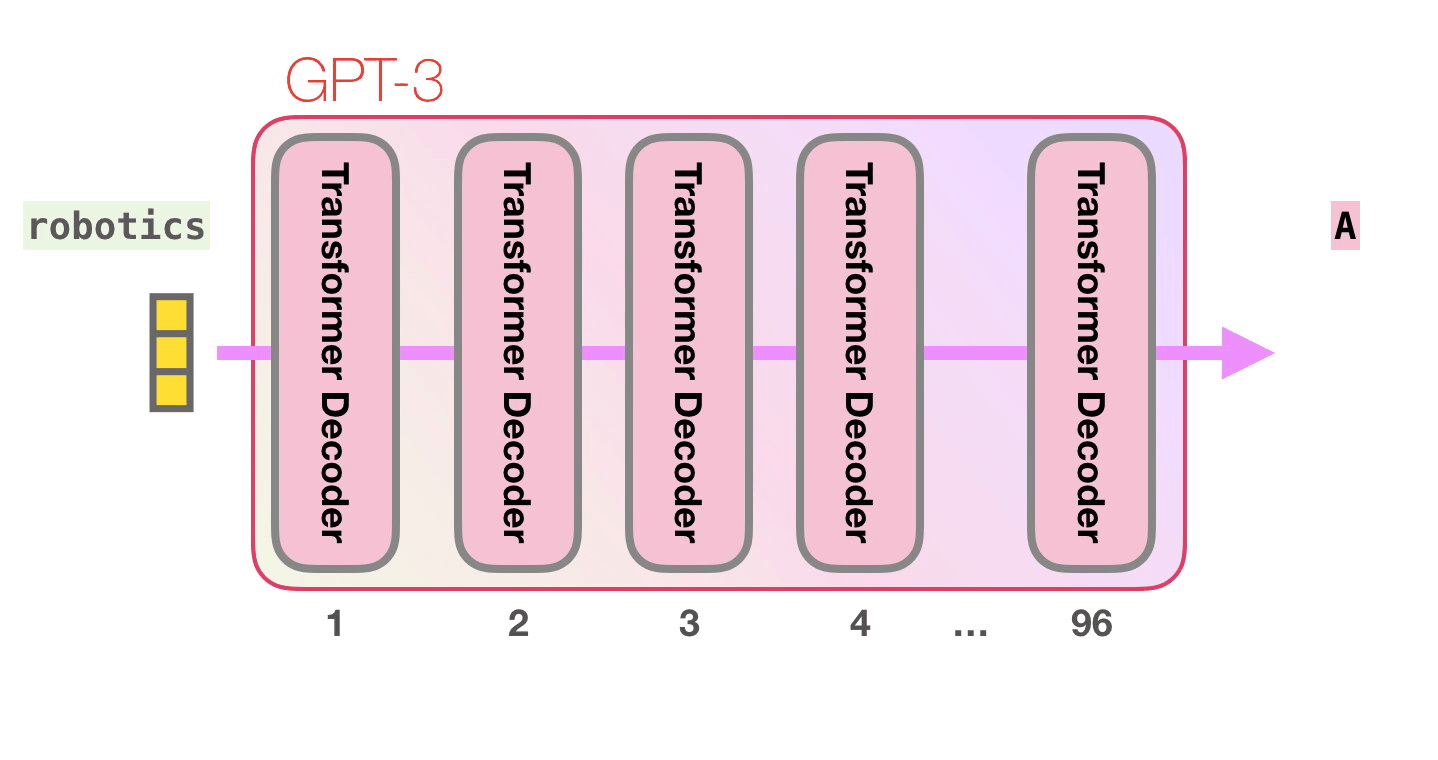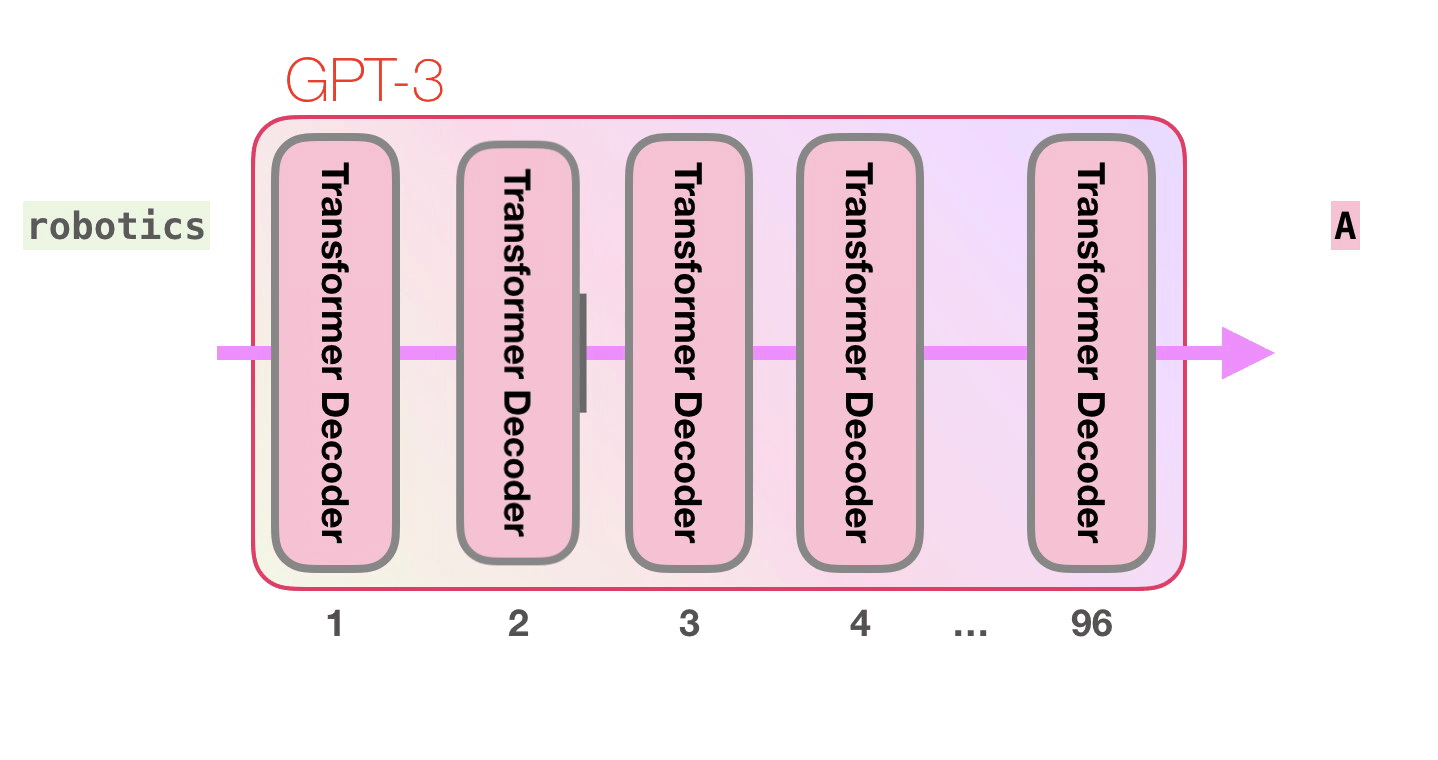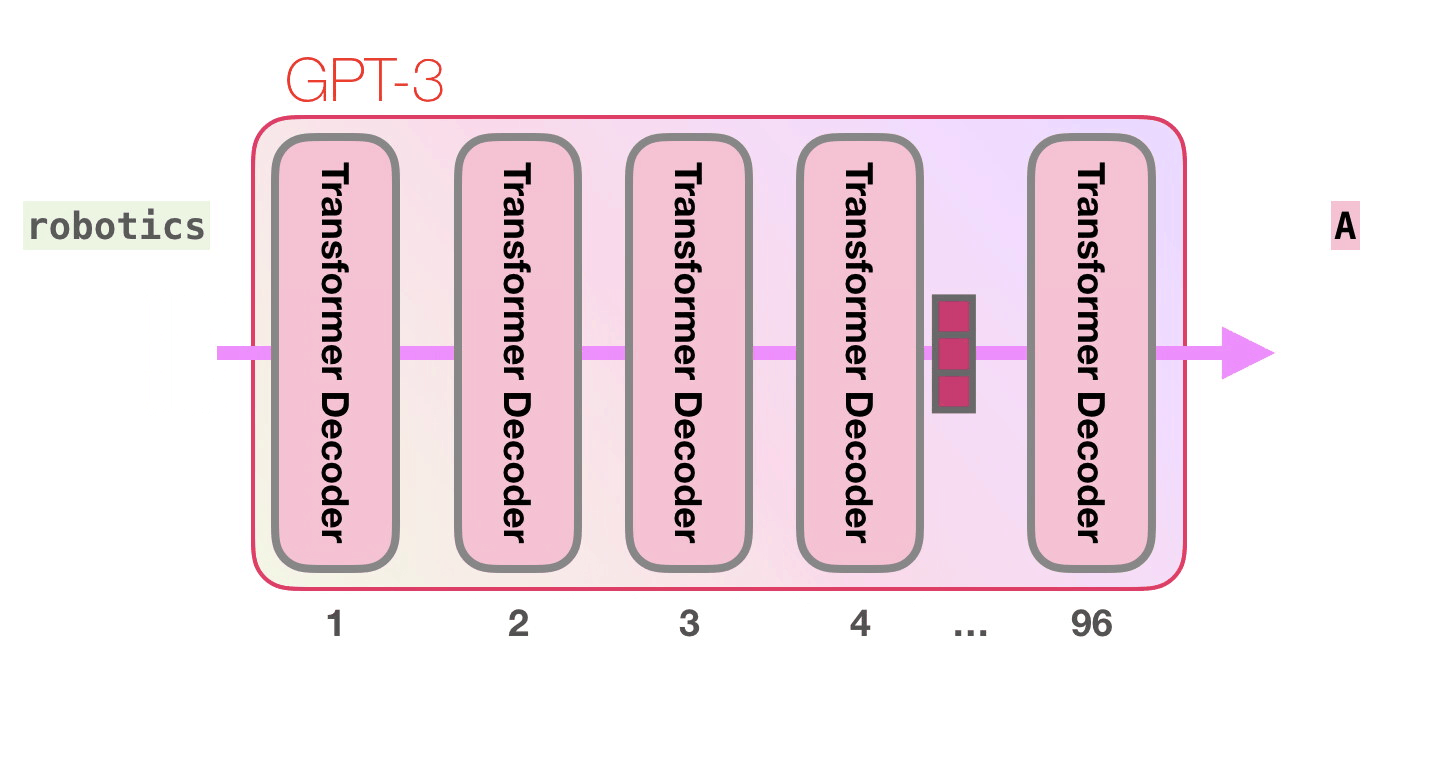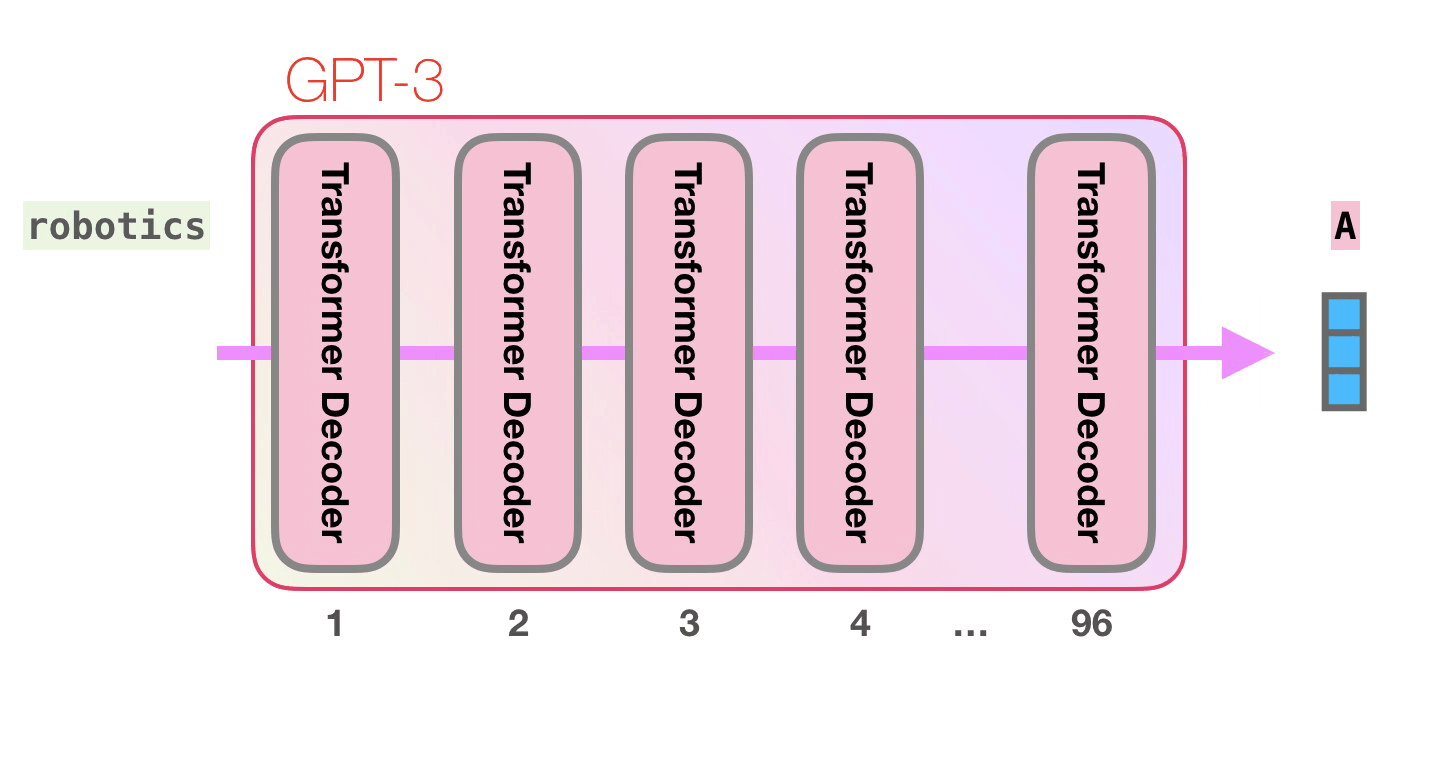
GPT3'ün önemli hesaplamaları, 96 transformatör kod çözücü katmanından oluşan yığının içinde gerçekleşir.
Bütün bu katmanları görüyor musun? Bu, “derin öğrenmenin” “derinliğidir”.
Bu katmanların her birinin hesaplamalarını yapabilmesi için kendine ait 1.8 milyar parametresi bulunmaktadır. İşte “sihir” burada gerçekleşir. Bu, söz konusu sürecin üst düzey bir görünümüdür:
Kod çözücünün içindeki her şeyin ayrıntılı açıklamasını blog yazım GPT-2 Transformatör Dil Modellerinin Görselleştirilmesi (The Illustrated GPT2)'de görebilirsiniz .
GPT3'ün farkı, dönüşümlü yoğun ve seyrek öz-dikkat katmanlarıdır .
Bu, GPT3 içindeki bir girdi ve yanıtın (“Tamam insan”) röntgenidir. Her tokenın katman yığınının tamamı boyunca nasıl aktığına dikkat edin. İlk kelimelerin çıktısı bizi ilgilendirmiyor. Giriş bittiğinde çıktıyla ilgilenmeye başlarız. Her kelimeyi modele geri besliyoruz.
React kod oluşturma örneğinde , birkaç açıklama=>kod örneğine ek olarak açıklamanın giriş istemi (yeşil) olacağını düşünüyorum. Ve reaksiyon kodu, buradaki pembe jetonların jeton üstüne jetonu gibi üretilecektir.
Benim varsayımım, örnekleri ve sonuçları ayıran belirli belirteçlerle birlikte, ön örneklerin ve açıklamanın girdi olarak eklendiği yönündedir. Daha sonra modele beslenir.

Bunun bu şekilde çalışması etkileyici. Çünkü GPT3 için ince ayar kullanıma sunulana kadar bekleyeceksiniz. Olasılıklar daha da şaşırtıcı olacak.
İnce ayar aslında modeli belirli bir görevde daha iyi hale getirmek için modelin ağırlıklarını günceller.
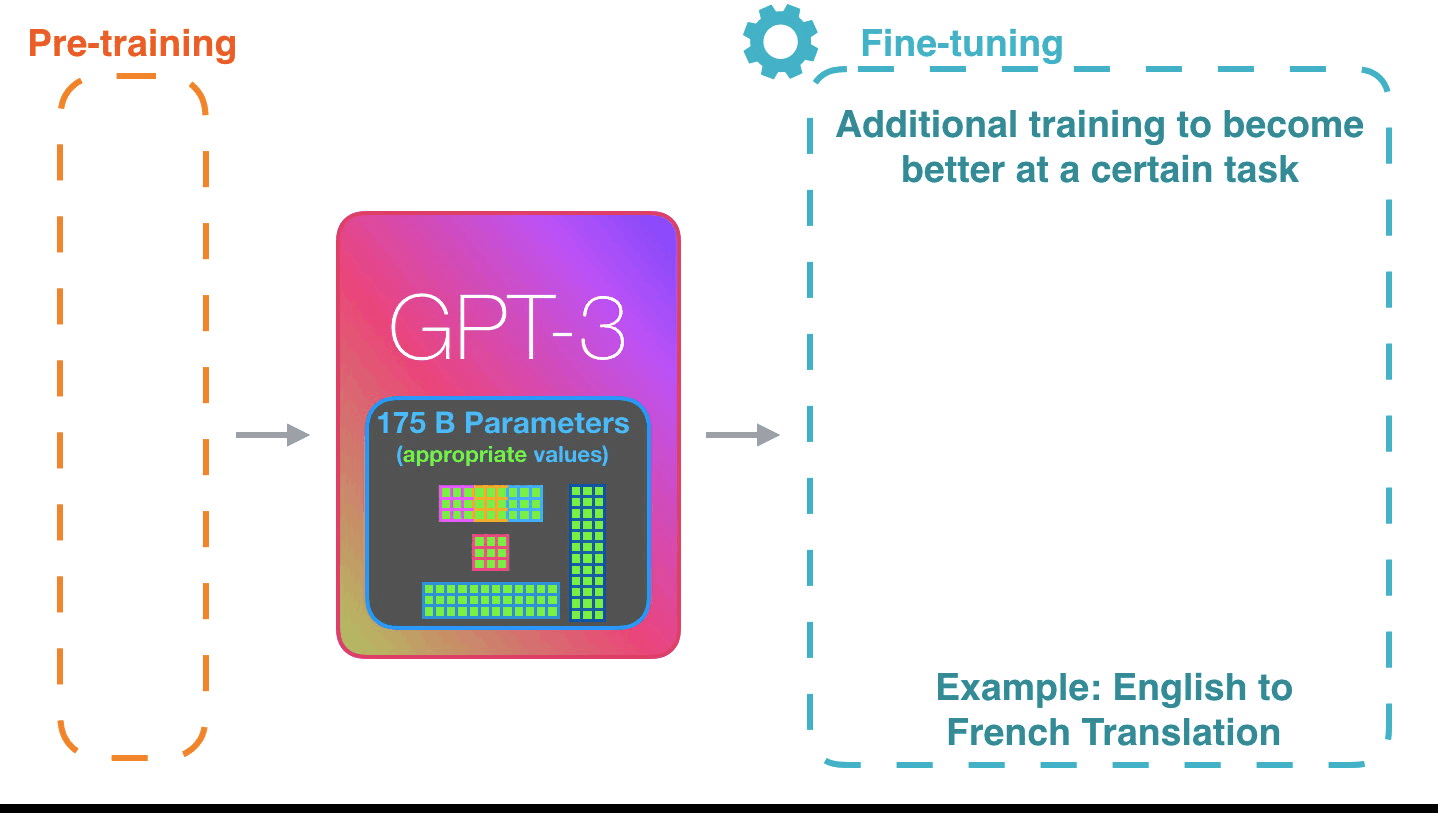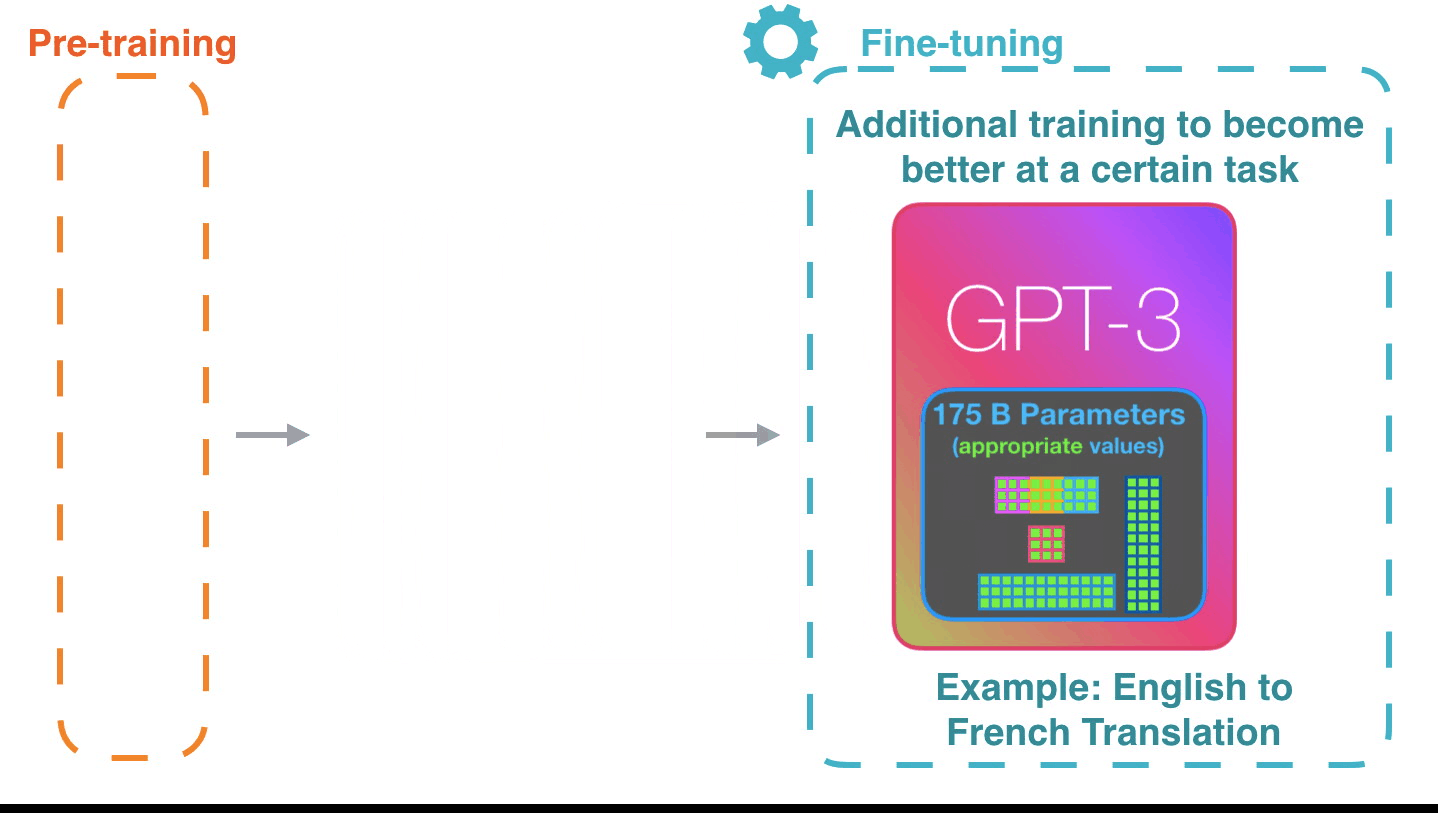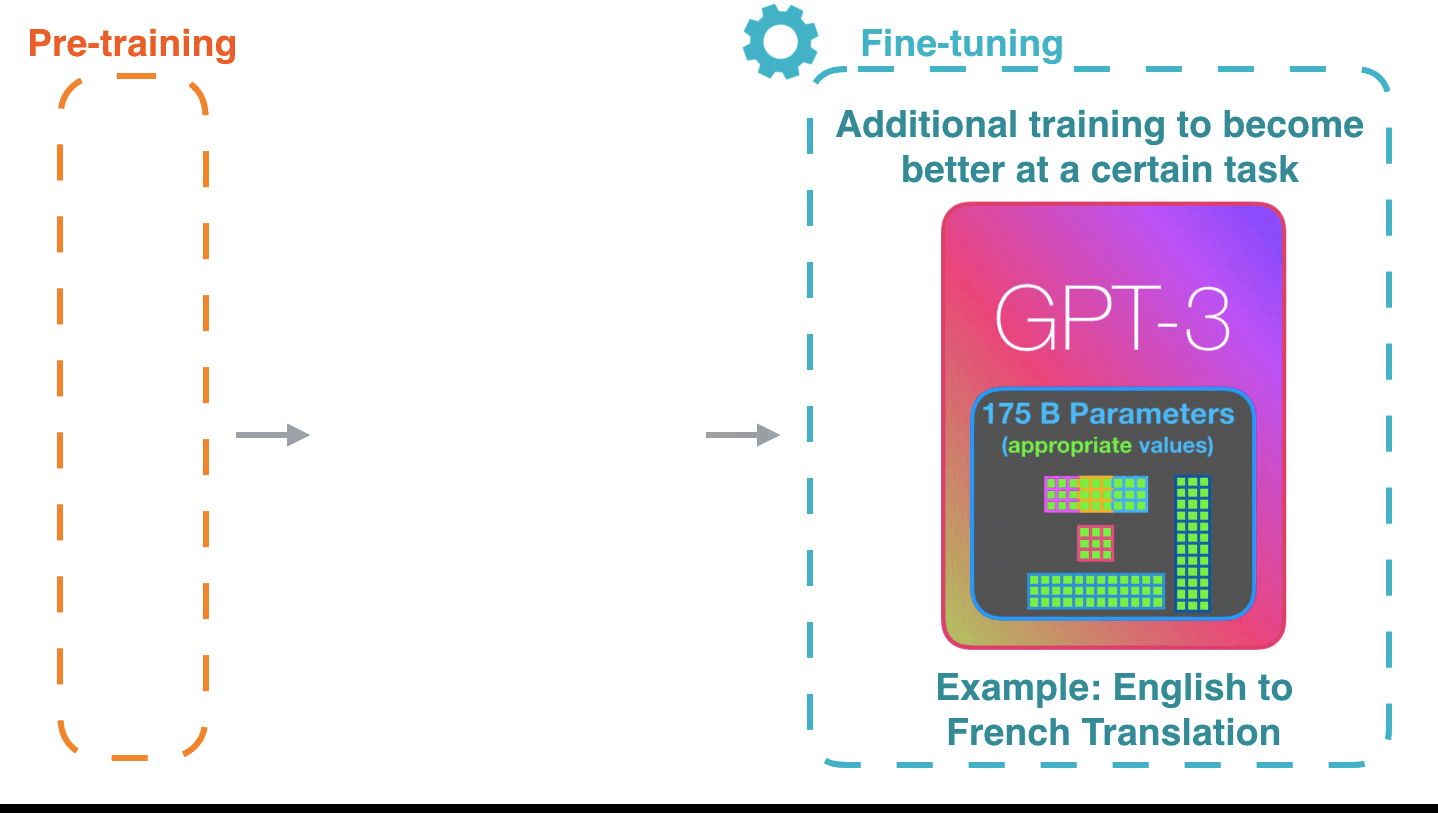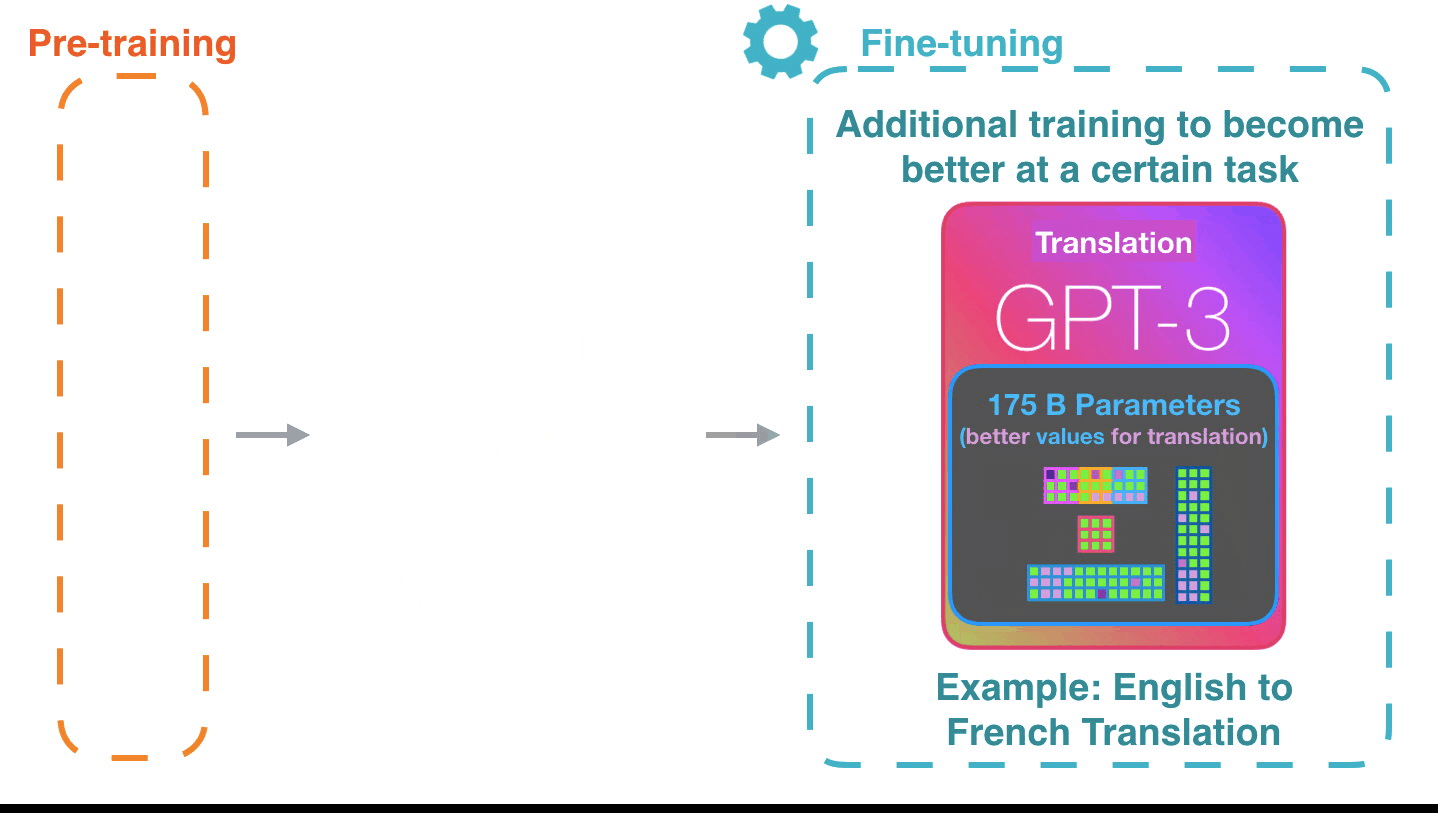
Referans; Jay Alammar
Alammar, J (2018). The Illustrated Transformer [Blog post]. Retrieved from https://jalammar.github.io/illustrated-transformer/
Visualizing machine learning one concept at a time.
@JayAlammar on Twitter. YouTube Channel
Devrim Danyal İrtibat & Sosyal Ağlar 📱
Akademi: https://www.devrimdanyalakademi.com
Twitter: http://twitter.com/devrimdanyal
LinkedIn: http://linkedin.com/in/devrimdanyal
YouTube: https://www.youtube.com/devrimdanyal
Instagram : https://www.instagram.com/devrimdanyal
Podcasts : https://open.spotify.com/show/6Im2GwBsAXZgysw2bIagXr
Medium: http://medium.com/@devrimdanyal
Konuşmacı Ajansları:
